- Code lineaire
-
Code linéaire
En mathématiques, plus précisément en théorie des codes, un code linéaire est un code correcteur.
Il est structuré comme un sous-espace vectoriel sur un corps fini. L'espace utilisé est souvent F2n le terme usuel est alors celui de code linéaire binaire.
Il est décrit par trois paramètres, [n, k, δ] n décrit la dimension de l'espace qui le contient. Cette grandeur est appelée longueur du code. k représente la dimension du code, correspondant à la taille des mots une fois décodés et δ décrit la distance minimale, au sens de Hamming entre chaque mot du code.
Les codes linéaires représentent l'essentiel des codes correcteurs utilisés dans l'industrie. Cette approche couvre en particulier les codes proposant une simple détection, une nouvelle émission est alors demandée. D'autres codes permettent une correction des altérations à l'aide d'une gestion fine de la redondance.
Rappel: F2 est l'unique corps à deux éléments et F2n est un espace vectoriel de dimension n. Si le corps de base est Fd, le corps contenant d éléments, le terme consacré est code linéaire de base d. La théorie des corps finis assure que d est une puissance d'un nombre premier et qu'il existe un unique corps possédant ce cardinal.
Sommaire
Approche intuitive
Code correcteur
Article détaillé : Code correcteur.Un code linéaire est un cas particulier de code correcteur. L'objectif est de permettre la correction d'erreurs après la transmission d'un message. Cette correction est permise grâce à l'ajout d'informations redondantes. Le message est plongé dans un ensemble plus grand, la différence de taille contient la redondance. Un exemple simple est celui du code de répétition, le message est, par exemple, envoyé trois fois, le décodage se fait par vote. Ici, l'ensemble plus grand est de dimension triple à celle du message initial.
Rappelons les éléments de base de la formalisation. Il existe un ensemble E constitué de suites de longueur k, c’est-à-dire qu'à partir du rang k, toutes les valeurs de la suite sont nulles, et à valeur dans un alphabet. Ces éléments sont l'espace des messages que l'on souhaite communiquer. Pour munir le message de la redondance souhaitée, il existe une application φ injective de E à valeurs dans F, l'espace des suites de longueur n à valeurs dans un alphabet. La fonction φ est appelée encodage, φ(E) est appelé le code, un élément de φ(E) mot du code, k la longueur du code et n la dimension du code.
Pour permettre d'utiliser la puissance des outils mathématiques, il peut être judicieux de d'utiliser des structures algébriques. les alphabets de E et F sont choisis comme un même corps fini. Les éléments de E (resp. F) sont les suites finies de longueur k (resp. n), E et F héritent naturellement d'une structure d'espace vectoriel de dimension finie et d'une base canonique, celle de l'espace des suites finies à valeurs dans un corps. L'application encodage est choisie linéaire.
L'espace F est muni d'une distance appelée distance de Hamming dérivant d'une pseudo-norme, le poids de Hamming. Le poids de Hamming p d'un point de F correspond au nombre de ses coordonnées non nulles. La distance de Hamming entre deux éléments de F est le poids au sens de Hamming de leur différence.
Domaine d'application
Article détaillé : Code cyclique.Les codes linéaires correspondent à une très large majorité de type de codes correcteur. Ils sont utilisés pour la détection d'altérations, avec comme méthode de correction associée une demande de retransmission, la technique utilisée la plus usuelle est alors la somme de contrôle. Elles sont utilisés dans une multitude de situations, depuis quelques erreurs isolées à de vastes altérations ou des phénomènes d'effacements.
Si le cadre utilisé est largement employé, il ne répond néanmoins pas à l'intégralité des besoins. On peut citer deux grands sujets, peu traités par la théorie des codes linéaires. Un bon code répond à un critère d'optimalité, il est dit parfait. Le cadre de la théorie des codes linéaires offre des critères pour valider cette optimalité. En revanche, il ne propose pas de méthode pour concevoir ce type de code.
Une méthode générale pour la correction des erreurs est disponible, le décodage par syndrome. Cette méthode consiste à créer une table associant à chaque erreur, sa solution. La table croît exponentiellement avec le nombre de lettres susceptible d'être erronées. Dans le cas d'une large capacité de correction, cette approche n'est plus opérationnelle.
La théorie des codes cycliques, utilisant largement les propriétés des corps finis répond à ces deux besoins. Un code cyclique est un code linéaire possédant une structure algébrique supplémentaire.
Définitions
-
- Soit p un nombre premier, d une puissance de p, n un entier strictement positif et k un entier plus petit que n. Un code linéaire C de dimension k et de longueur n est un sous-espace vectoriel de Fdn de dimension k. Si d est égal à deux, le code est dit binaire sinon on parle de code linéaire de base d.
Ici, Fd désigne l'unique corps à d éléments (cf l'article corps fini). On remarque que l'espace vectoriel des suites à valeurs dans Fd est identifié à Fdn. L'espace vectoriel Fdn est muni de la distance de Hamming.
Comme pour les autres codes correcteurs, la notion de paramètres s'applique. Cependant, pour tenir compte de la structure d'espace vectoriel, elle est un peu modifiée:
-
- Les paramètres d'un code sont notés [n, k, δ] ou δ désigne la distance minimale entre deux points du code.
La définition de paramètre pour les codes linéaires n'est donc pas compatible avec celle, plus générique utilisées pour les codes correcteurs. Pour cette raison, traditionnellement les paramètres d'un code linéaire sont notés [n, k, δ] et ceux d'un code correcteur général {n, M, δ}.
Comme précédemment, il existe une application d'encodage : φ.
-
- L'application d'endocage φ d'un code linéaire est une application linéaire injective de Fdk dans Fdn.
-
- La matrice G de Fdn dans les bases canoniques est dite matrice génératrice du code C. Elle vérifie l'égalité suivante:
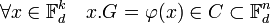
Le contrôle permettant la vérification et les éventuelles corrections est donné par une application linéaire h de Fdn dans Fdn-k ayant pour noyau C. La théorie de l'algèbre linéaire montre qu'une telle application existe, il suffit par exemple de considérer un projecteur sur un sous-espace supplémentaire de C parallèlement à C.
-
- La matrice H de h dans les bases canoniques est dite matrice de contrôle du code C. Elle vérifie les propriétés suivantes:
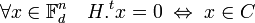
Le terme de matrice de parité est aussi utilisé pour désigner la matrice de contrôle.
Remarque : Ces notations sont utilisées dans le reste de l'article.
Propriétés
Toutes les propriétés de l'algèbre linéaire s'appliquent aux codes linéaires. Le code est ainsi à la fois plus facile à implémenter et à décoder. De plus les outils de génération d'espace vectoriel comme l'espace dual ou le produit tensoriel permettent de concevoir des nouveaux codes, parfois plus adaptés aux contraintes industrielles.
Matrice génératrice
Article détaillé : Matrice génératrice.L'application d'encodage est linéaire, elle se représente donc et se calcule grâce à sa matrice génératrice. Un code est entièrement défini par sa matrice génératrice, de dimension nxk. De plus comme les propriétés de son code ne dépendent que de la géométrie φ(E). Si f est un isomorphisme de E, le code défini par l'application φof est le même que celui de φ. Ce qui donne lieu à la définition suivante :
-
- Deux codes sur un même alphabet Fd de longueur k définis par deux matrices génératrices G et G' tel qu'il existe une matrice carrée inversible P d'ordre k vérifiant G =G'.P sont dits équivalents.
Il existe une forme particulièrement simple pour la matrice G :
-
- Un code linéaire dont la matrice génératrice possède pour k premières lignes une matrice identité d'ordre k est dit code systématique.
L'article associé à ce paragraphe démontre une propriété importante :
-
- Tout code linéaire est équivalent à un code systématique.
Cette écriture accélère et simplifie l'encodage et le décodage. La matrice prend alors la forme suivante :
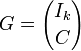
Les coordonnées de la matrice C correspondent à la redondance, leur objectif est la détection et la correction d'erreurs éventuelles:
-
- Les n - k dernières coordonnées d'un mot du code systématique sont dites bits de contrôle ou parfois somme de contrôle.
Matrice de contrôle
Article détaillé : Matrice de contrôle.Dans le cas linéaire, le code est un sous-espace vectoriel de dimension k. Il existe alors une application linéaire surjective de F dans un espace de dimension n - k ayant pour noyau exactement le code :
-
- Une matrice de contrôle d'un code φ(E) est une matrice H de dimension nxn - k tel que :
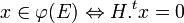
Dans le cas d'un code systématique, l'expression de la matrice génératrice offre immédiatement celle d'une matrice de contrôle.
-
- Dans le cas d'un code systématique, si G est l'expression d'une matrice génératrice alors l'expression suivante est celle d'une matrice de contrôle :
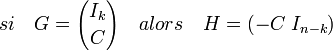
Ici, Ik désigne la matrice carrée identité d'ordre k. Cette matrice offre une manière relativement simple de calculer la distance minimale :
-
- La distance minimale δ d'un code linéaire est égale à la dimension du plus petit sous-espace vectoriel S de F généré par des éléments de la base canonique et tel que la restriction de la matrice de contrôle à S soit non injective.
Distance de Hamming
Article détaillé : Distance de Hamming.Dans le cas d'un code linéaire, la distance de Hamming s'exprime comme une distance issue d'une pseudo-norme. Le poids de Hamming, qui à un code associe le nombre de coordonnées non nulles, joue ici le rôle de pseudo-norme.
-
- Si ω désigne le poids de Hamming pour un code linéaire C, alors la distance de Hamming d est définie par la formule suivante:
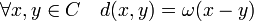
La linéarité de la structure sous-jacente introduit une propriété directe:
-
- La distance minimale δ entre deux points du code est égale au minimum du poids des mots du code non nuls.
Pour s'en convaincre, il suffit de remarquer que si x et y sont deux mots du code, alors leur différence est aussi un mot du code.
Borne de Singleton et code MDS
Article détaillé : Code parfait et code MDS.Le nombre maximum d'erreurs assurément corrigibles t découle directement de la distance minimale δ. En effet, t est le plus grand entier strictement inférieur à δ/2. La situation idéale est celle où les boules fermées de centre les mots du code et de rayon t forment une partition de F. On parle alors de parfait.
-
- La majoration suivante est vérifiée pour tous les codes linéaires. Elle se nomme borne de Singleton:
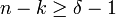
Si la borne de Singleton est atteinte, le code est dit MDS.
Code dual
Article détaillé : Espace dual.La structure linéaire du code donne naturellement naissance à la notion de code dual. Si l'espace vectoriel contenant C est muni d'une structure dual à l'aide du produit scalaire canonique, alors le code C possède naturellement un espace vectoriel dual supplémentaire.
-
- Le code dual d'un code linéaire C est le sous-espace supplémentaire orthogonal à C si l'espace est muni du produit scalaire canonique. C'est un code de même longueur et de dimension n - k. Il est souvent noté
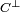 . Un code est dit autodual s'il est égal à son dual.
. Un code est dit autodual s'il est égal à son dual.
- Le code dual d'un code linéaire C est le sous-espace supplémentaire orthogonal à C si l'espace est muni du produit scalaire canonique. C'est un code de même longueur et de dimension n - k. Il est souvent noté
Dans le cas d'un code systématique, cas où il est toujours possible de se ramener, la matrice de contrôle de C devient une matrice génératrice de son dual. Il suffit alors de réordonnancer la base pour obtenir un code systématique. De même une matrice génératrice de C est une matrice de contrôle de son dual.
Il est possible de calculer la distance minimale de
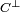 à partir de C, toutefois il n'est pas suffisant de connaitre celle de C : il faut connaitre le polynôme énumérateur des poids de C. L'identité de MacWilliams donne alors celui de d'où on extrait simplement la distance minimale de ce dernier.
à partir de C, toutefois il n'est pas suffisant de connaitre celle de C : il faut connaitre le polynôme énumérateur des poids de C. L'identité de MacWilliams donne alors celui de d'où on extrait simplement la distance minimale de ce dernier.Code produit
Article détaillé : Produit tensoriel.L'algèbre linéaire offre de multiples autres techniques compatibles avec les codes. Le produit tensoriel est un exemple. À deux espaces vectoriels, il en associe un troisième isomorphe aux applications linéaires du premier espace dans le deuxième.
-
- Si C0 (resp. C1) est un code linéaire de paramètre [n0, k0, d0] (resp. [n1, k1, δ1]), alors le produit tensoriel des deux codes est un code de paramètre [n0.n1, k0.k1, δ0.δ1]. Ce code est appelé code produit de C0 et C1.
Il permet de corriger toute configuration comportant moins de δ0.δ1/4 erreurs.
Traitement des erreurs
Détection
Article détaillé : Somme de contrôle.La technique la plus simple de traitement des erreurs se limite à une validation. Si le message n'est pas élément du code, alors il est déclaré faux. En général, une nouvelle demande de transmission est la technique de correction.
La méthode la plus fréquemment utilisée consiste à adjoindre au message un ou plusieurs bits de contrôle correspondant à la somme dans le corps fini des coefficients du message. Cette technique est l'analogue de la preuve par neuf.
Quitte à augmenter le nombre de bits de contrôle, cette méthode peut accroitre son niveau de fiabilité. Si la probabilité est suffisamment forte pour supposer qu'une seule erreur est à même de se glisser dans le message, alors un bit de contrôle remplit la condition.
Dans le cas d'un unique bit de contrôle, alors les paramètres du code sont [n, n - 1, 2]. Un tel code ne peut pas procéder à la correction de l'erreur par lui-même. En effet pour chaque erreurs, il existe n - 1 points du code qui sont proches. Des informations supplémentaires sont nécessaires pour une auto-correction.
L'implémentation est simple, le calcul de l'image du message par la matrice de contrôle fournit l'information. Si l'image est nulle alors le message correspond à un code et il est sans erreur, sinon une erreur est déclarée.
Correction
Article détaillé : Décodage par syndrome.La question est ici traitée uniquement dans le cas des codes systématiques. Non seulement c'est la solution considérée par l'industrie, mais de plus, toute autre configuration est équivalente à celle-là.
Dans un premier temps, il est possible de considérer uniquement le problème au vecteur nul. Le message reçu possède donc comme k premières coordonnées 0 et des bits de contrôle c non tous nuls. Cette situation correspond à une erreur, car l'image du vecteur nul par la matrice génératrice donne le vecteur nul et donc les bits de contrôle sont tous nuls pour un code ayant ses k premières coordonnées nulles.
La correction correspond au message m de plus petit poids de Hamming et ayant pour image par la matrice de contrôle -H.c. Si le nombre altérations ayant générées le vecteur (0, c) est inférieur à (δ - 1)/2, alors il existe un unique m tel que H.m = -H.c. Ici, H.c désigne par abus le vecteur H.(0,c). Le code associé est m - c et le message initial est m. On vérifie de fait que H.(m - c) = 0 et m - c est un code. Il est alors possible, à chaque valeur de H.c, d'associer une correction m.
-
- La valeur H.(0,c) où H est une matrice de contrôle systématique et c un ensemble de bits de contrôle non nuls est appelée un syndrome.
Dans le cas général, si l est un message reçu qui n'est pas élément du code, son image par la matrice de contrôle est une valeur correspondant à un H.c donné. Il apparait que m est la plus petite correction à appliquer à l pour obtenir un code. En effet, H(l + m) est égal à H.c - H.c et la minimalité est une conséquence du paragraphe précédent.
La détermination de la valeur m pour un H.c dépend largement du choix du code. Il correspond au problème classique couvert par la programmation linéaire. Dans la pratique, il est rare que de telles méthodes soient employées. Soit les bits de contrôles sont en nombre réduits, et la combinatoire est réduite, soit l'espace est vaste et le code dispose d'autres propriétés souvent polynomiales et décrite dans l'article code cyclique.
L'implémentation, dans la mesure où l'espace des bits de contrôle est réduit est en général réalisée par une table de hachage. Cette table établit une bijection entre chaque syndrome et le message de poids minimal ayant pour image par la matrice de contrôle le syndrome.
-
- Une implémentation de la correction à l'aide d'une table de hachage fournissant une bijection entre les syndromes et les messages de poids minimal est appelée un décodage par syndrome.
Notes et références
Liens externes
- (fr) Code correcteur C.I.R.C par J.P. Zanotti
- (fr) L'algèbre et la correction des erreurs par Dany-Jack Mercier Université Antilles-Guyane
- (fr) Code Linéaire Université de Bordeaux
- (fr) Cours de code par Christine Bachoc Université de Bordeaux
- (fr) Code correcteur par M. Coste, A. Paugam, R. Quarez Université de Lille
Références
- FJ MacWilliams & JJA Sloane The Theory of Error-Correcting Codes North-Holland, 1977
- A Spataru Fondements de la Théorie de l'Information Presses Polytechniques Romandes, 1991
- M. Demazure Cours d'algèbre Cassini, 1997
 Portail des mathématiques
Portail des mathématiques
Catégories : Détection et correction d'erreur | Algèbre linéaire | Corps fini -
Wikimedia Foundation. 2010.