- Optimisation des performances des architectures multi-cœurs
-
Un microprocesseur multi-cœur (multi-core en anglais) est un processeur possédant plusieurs cœurs physiques. Depuis l’arrivée des premiers microprocesseurs double cœurs en 2005, le nombre de cœurs ne cesse d’augmenter dans l’objectif d’améliorer toujours plus la puissance des ordinateurs. On observe cependant un certain nombre de problèmes dues à l’augmentation du nombre de cœurs, et cette simple amélioration technique ne suffit parfois pas à améliorer de façon significative les performances d’un ordinateur.
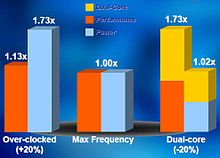 Comparatif des performances entre un processeur en conditions normales, le même dans un état en sur alimentation électrique, et enfin un double cœur à base de 2 processeurs identiques au premier mais en sous alimentation électrique.
Comparatif des performances entre un processeur en conditions normales, le même dans un état en sur alimentation électrique, et enfin un double cœur à base de 2 processeurs identiques au premier mais en sous alimentation électrique.
D’un point de vue technologique, les constructeurs semblent être arrivés devant un mur de fréquence. L’amélioration des performances passe donc aujourd’hui par d’autres évolutions technologiques et, parmi elles, l’augmentation du nombre de cœurs. Cela amène à de nouveaux défis technologiques tels que la gestion des ressources pour alimenter tous les cœurs ou comment réussir à augmenter le nombre de cœurs sur une même puce avec des contraintes telles que gestion de la place, de la chaleur ...
Ces défis technologiques ne suffisent pourtant pas à augmenter de façon significative les performances. Pour pouvoir en tirer profit, ce matériel doit pouvoir être pris en compte par les différents systèmes d’exploitation. Or, à l’heure actuelle, ces derniers n’arrivent pas à exploiter 100% des possibilités.
Sommaire
Les contraintes dues à l’augmentation du nombre de cœurs
Au niveau du matériel (hardware)
Le bruit thermique
D'une part[1], l'évolution technologique permet de doubler le nombre de transistors par unité de surface à chaque incrémentation technologique. Aussi, dans l'idéal, les tensions d'alimentation sont réduites de manière appropriée afin de réduire le bruit thermique. Cependant, les contraintes sont tellement fortes qu'il est maintenant difficile d'apporter de réelles améliorations à chaque incrémentation technologique. En effet, n'ayant pas les moyens de maîtriser parfaitement les tensions idéales, l'augmentation de la puissance de calcul et la miniaturisation des puces conduit à des températures plus élevées sur ces dernières. Ces températures élevées pourraient être dissipées à condition d'améliorer les systèmes de refroidissement. Cependant, des améliorations dans ces techniques de dissipation thermique sont complexes et encombrantes, les rendant économiquement et ergonomiquement pas intéressantes.
La miniaturisation des puces a atteint un seuil tel que les fuites de courant électrique produisent un important bruit thermique[1]. Aussi, ces fuites de courant électrique doivent être compensée afin d'acheminer toute l'énergie nécessaire au bon fonctionnement du processeur, entraînant une surconsommation globale du processeur. En outre, l'augmentation des températures peut d'une part causer des dommages physiques permanents à la puce et peut d'autre part dilater les matériaux et donc augmenter les délais de communication au sein du circuit. En général, l'augmentation des températures sur la puce est préjudiciable aux performances du processeur, à sa puissance et à sa fiabilité.
Ainsi, de nouvelles solutions[1] pour outre-passer ces limites thermiques sont nécessaires. Même si les transistors plus petits ont le potentiel d'être utilisés à des fréquences élevées, les contraintes thermiques continuent de restreindre leurs fréquences de fonctionnement. Les concepteurs de puces ont atténué les complications thermique par l'utilisation des architectures multi-cœurs, qui continuent d'augmenter le débit du système. Plutôt que de se concentrer sur l'amélioration des performances sur un seul thread[2], les architectures multi-cœurs permettent d'avoir plusieurs cœurs indépendants qui effectuent simultanément des calculs différentes. Toutefois, étant donné qu'il existe plusieurs unités de traitement indépendantes, les faire travailler à des fréquences modérées ne permet pas encore d'obtenir des gains de performance importants. Avec une quantité idéale de parallélisme au niveau thread (TLP), les performances peuvent presque doubler à chaque nouvelle génération technologique. Cependant, une charge de travail donnée a une limite fondamentale à la concurrence[3]. Ainsi, cette situation peut se produire lorsque tous les cœurs dans un processeur multi-cœurs ne peuvent pas être utilisés. En fait, le codage et la compilation de TLP est l'un des défis les plus difficiles pour les processeurs multi-cœurs.
Ces dernières années, la gestion dynamique thermique (DTM) est apparue dans les états de l'art comme une méthode pour faire face à des contraintes thermiques liées aux processeurs[1]. Les méthodes DTM permettent de consulter l'état thermique actuel d'un processeur. Pour se faire, ces informations sont récoltées soit directement au moyen de capteurs de température, soit indirectement à l'aide des analyseurs de performance. Ensuite, des modifications sont apportées aux paramètres de configuration du processeur de façon à régler sa température de manière appropriée. La plupart des techniques DTM entrainent une certaine forme de perte de performances. Par exemple, en diminuant la largeur du pipeline (i.e.: en diminuant le nombre de transistors), la quantité d'énergie dissipée sera diminuée également, mais, en contre-partie, les cycles par instruction seront augmentés. La recherche sur les techniques de DTM tente de maitriser les contraintes thermiques, tout en minimisant la dégradation des performances. L'une des techniques importantes en DTM est la capacité de contrôler dynamiquement l'exploitation physique des paramètres, à savoir, la fréquence et la tension de chaque cœur.
Un espace restreint
D'autre part[4], au fur et à mesure que les microprocesseurs se sont miniaturisées, les réseaux de connexions entre les différents éléments constitutifs de ces puces se sont densifiés. Ainsi, les interconnexions au sein des microprocesseurs récents imposent des contraintes majeures au niveau de leurs performances. En effet, aujourd'hui, avec l'augmentation régulière du nombre de cœurs au sein des processeurs multi-cœurs, la densification des interconnexions au sein de ces puces ne cesse d'augmenter également (jusqu'au jour où nous n'aurons plus suffisamment de place sur les puces pour tisser ces réseaux de communication). Pour cette raison, l'augmentation du nombre de cœurs sur les puces afin d'améliorer les performances amène inévitablement à la situation où les interconnexions deviennent le goulot d'étranglement de cette quête de performances.
Ainsi, l'utilisation de circuits intégrés en 3D est une solution permettant de contourner le manque d'espace sur les puces.
Les solutions matérielles étudiées dans ce document
Dans la suite de notre document, afin de répondre à nos deux problématiques d'ordre matériel (hardware) évoquées ci-dessus, une première section proposera une solution permettant de trouver la fréquence optimale et le réglage de la tension idéal de chaque noyau dans un système multi-cœur de telle sorte que l'impact de la contrainte thermique soit le plus petit possible lors de l'exécution et que la performance physique totale soit maximisée, et une deuxième section nous présentera en quoi l'utilisation de circuits intégrés en 3D est une solution permettant de contourner le manque d'espace sur les puces malgré les contraintes que cette nouvelle technologie impose (car il y en a!).
Gestion des ressources
L'augmentation du nombre de cœurs dans les microprocesseurs est une conséquence de l’évolution du matériel. On note cependant de nombreuses répercutions sur les systèmes d’exploitations et plus précisément sur la gestion des ressources par ces derniers. Dans le cas des processeurs mono-cœur, le modèle de Von-neumann a su s’imposer comme un modèle de référence tant qu’au niveau des logiciels qu’un niveau des systèmes d’exploitations grâce à sa simplicité.
Depuis l'apparition des premiers processeurs double-cœurs en 2005, aucun modèle n’arrive à s’imposer comme celui de Von-Neumann pour les microprocesseurs mono-cœur. Cela ne va sans poser de problème. Depuis maintenant 5 ans, le nombre de cœurs dans nos machines ne cesse de croitre en passant d’abord de 2 à 3 puis 4, 6 et maintenant 8 cœurs sur la même puce dans les machines grand publique et jusque 80 cœurs par puce dans les stations de recherche. Bien qu’en théorie chaque cœur permettent de doubler la puissance de calcul de la puce et par conséquent de l’ordinateur, cela ne s’avère pas exacte dans la pratique.Le gain de performance peut se calculer avec la Loi d'Amdahl et on observe des résultats inférieurs à 1 même pour les applications qui se prête bien au parallélisme. Cela s’explique de deux façons différentes :
- Des applications ou algorithmes qui ne sont ou ne peuvent pas ou peu être parallélisé.
- La gestion des ressources des ressources par les systèmes d’exploitations.
Ce second point peut s’expliquer avec la gestion de l’ordonnancement, la gestion des caches ou encore la communication inter-cœurs et/ou processeurs. On verra dans la seconde partie, qu’il existe plusieurs piste afin d’améliorer les performances pour les systèmes multi-cœurs.
Améliorations apportées au niveau du matériel
Le rapport performance / consommation
Le principe
Le travail réalisé par Michael Kadin et Sherief Reda (Division of Engineering - Brown University)[5] vise à trouver la fréquence optimale et le réglage de la tension idéal de chaque noyau dans un système multi-cœur de telle sorte que l'impact de la contrainte thermique soit le plus petit possible lors de l'exécution et que la performance physique totale soit maximisée. Pour ce travail, la performance physique totale est définie comme la somme des fréquences d'horloge de tous les conducteurs. Bien que n'étant pas tout à fait exact, la somme des fréquences est un choix raisonnable, et il est généralement corrélé avec le débit total du système, surtout si la charge de travail est bien répartie entre les différents cœurs.
Dans de nombreux systèmes multi-cœurs, trouver les réglages optimaux des paramètres de fonctionnement par énumération exhaustive est impossible à calculer à la volée (au cours de l'exécution des processus) en raison de la complexité combinatoire de l'espace de recherche. Ainsi, pour trouver les fréquences et les tensions optimales au cours de l'exécution, il est nécessaire de faire abstraction de la complexité de la conception d'un processeur dans une formulation mathématique qui peut être rapidement résolue durant le fonctionnement de ce processeur au titre des objectifs d'optimisation et contraintes.
Pour formuler un tel modèle mathématique, Michael Kadin et Sherief Reda se sont heurtés à quelques complications[5] dont voici les raisons:
- Tout d'abord, au sein de la puce, la chaleur se propage dans les trois dimensions. Ainsi, la puissance thermique libérée par une unité (ici, un transistor) au sein du processeur peut voyager via la matière constituante du processeur et être transmise latéralement à d'autres unités à proximité. De ce fait, la température d'une unité ne dépend pas seulement de la puissance dissipée par cette unité, mais également de celle dissipée par les unités voisines.
- Une deuxième complication survient avec l'augmentation de la température. En effet, comme nous venons de le voir, ceux sont les fuites de courant qui augmentent la température, mais cette augmentation de la température dilate les matériaux et entraîne à son tour une amplification du phénomène de fuites de courant et avec lui une augmentation de la consommation électrique. Par conséquent, la température et la consommation électrique sont étroitement liées par les dépendances due aux fuites de courant (LDT).
- Troisièmement, le pouvoir de dissipation de la chaleur n'est pas le même partout dans la puce. En effet, une unité au centre de la puce aura plus de mal à dissiper sa chaleur qu'une unité en périphérie qui a moins de voisines et qui, donc, subit moins le rayonnement thermique de ses voisines.
Résultats expérimentaux
Ainsi, c'est dans cet objectif que Michael Kadin et Sherief Reda proposent de nouvelles techniques afin de maximiser les performances des processeurs multi-cœurs en prenant compte des contraintes thermiques[6]. L'utilisation de machines d'apprentissages leurs ont permis de proposer un modèle simple qui peut décrire mathématiquement les caractéristiques thermiques des processeurs multi-cœurs en fonction de leurs paramètres de fonctionnement en entrée. Étant donné les valeurs des mesures effectuées par les capteurs thermiques placés sur la puce, ce modèle permet de calculer la température maximale autorisée avec une précision raisonnable. Le modèle se transpose naturellement à un programme linéaire de formulation des optimisations. Michael Kadin et Sherief Reda ont examiné différentes situations où le programme linéaire calcule les fréquences et les plans de tension optimaux qui offrent des performances supérieures par rapport aux choix standards. En outre, l'environnement d'optimisation développé ici est polyvalent. En effet, il est possible de l'utiliser sur un et un seul cœur ou sur un ensemble de cœurs en simultanéité. La fréquence et la tension peuvent être bien intégrés dans un système de gestion dynamique thermique (DTM) pré-existant. Un tel système permet d'ajuster la fréquence et la tension de chaque cœur en cours d'exécution pour tenir compte des variations thermiques non modélisées.
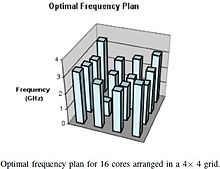 Répartition optimale des fréquences de chacun des 16 cœurs d'un processeur multicœur 4x4 (en tenant compte des contraintes thermiques au sein de la puce).
Répartition optimale des fréquences de chacun des 16 cœurs d'un processeur multicœur 4x4 (en tenant compte des contraintes thermiques au sein de la puce).Il y a des limites sur les possibilités de parallélisme qu'une charge de travail peut avoir au niveau des threads[3]. En conséquence, il peut arriver que tous les cœurs d'un système multi-cœurs ne soient pas en cours d'utilisation. Michael Kadin et Sherief Reda ont montré que l'utilisation de modélisations mathématiques peuvent aider à augmenter les performances d'un système avec des cœurs au repos[6]. En effet, leur méthode permet de redistribuer les charges de travail en ajustant les fréquences des cœurs tout en s'assurant de ne pas dépasser les températures limites tolérées par eux-mêmes. Cette méthode prend en compte la répartition spatiale des cœurs au repos sur la puce ainsi que l'état thermique de chaque cœur afin de recalculer les fréquences optimales à attribuer à chaque cœur dans le but de réorganiser les charges de travail sur la puce et, par conséquent, de contrôler les dégagements thermiques en chacune des zones de la puce. Cette technique est très prometteuse sachant que les architectures multi-cœurs actuelles ne sont pas nécessairement conçues dans le but de faire du pur parallélisme de niveau thread et que, de ce fait, un cœur au repos peut être mis à profit dans un souci de limiter les pertes énergétiques sous forme thermique.
Les limites liées à la place disponible sur la puce
Récemment, afin de poursuivre l'amélioration des performances, l'utilisation de circuits intégrés en 3D a permis la conception de processeurs multi-cœurs[4]. Dans ces puces 3D, plusieurs couches sont empilées verticalement et les composants de ces différentes couches sont directement reliés verticalement par le biais de silicium Vias (SV). L'architecture des processeurs multi-cœurs en 3D a aussi l'avantage d'améliorer les performances en réduisant de façon spectaculaire la longueur des fils, et par conséquent, en réduisant les délais de communication des réseaux d'interconnexions. Enfin, réduire la longueur des fils a également un impact significatif sur la réduction de la consommation d'énergie en raison d'une plus faible probabilité d'avoir des fuites de courants. Ainsi, pour des raisons de:
- gain de place,
- d'amélioration des performances,
- d'économie d'énergie,
les circuits intégrés en 3D peuvent être une bonne solution pour l'avenir des microprocesseurs.
Mais, malgré les avantages mentionnés ci-dessus, l'utilisation de circuits intégrés en 3D a amené Young Jin Park et son équipe[4] à se poser certaines questions importantes. En effet, l'architecture des processeurs multi-cœurs en 3D soulève le problème de dissipation de la chaleur afin d'éviter la surchauffe de la puce. Cette problématique d'ordre thermique est accentuée pour deux raisons principales.
- La première est que les couches de silicium empilées verticalement empêchent une bonne dissipation de la chaleur (surtout pour les couches situées au centre).
- L'autre est que le silicium et le métal ont une forte conductivité thermique.
En outre, le mécanisme de refroidissement doit prendre en compte le fait qu'il se produit un transfert de chaleur entre les couches adjacentes. Pour cette raison, il est nécessaire de mettre en place des méthodes et techniques de refroidissement plus avancées afin d'éviter la surchauffe des architectures à processeurs multi-cœurs en 3D.
Un grand nombre de techniques, telles que les techniques DFS (dynamic frequency scaling) ou encore les techniques DTM (Dynamic Thermal Management) évoquées précédemment, ont été proposées[7] pour soulager le stress thermique subi par les puces en 2D (celles à une seule couche). Ces techniques permettent de résoudre la problématique thermique par la régulation de la température moyenne. Depuis, de nouvelles problématiques de dissipation de la chaleur sont apparues avec le développement des puces en 3D. Ainsi, des techniques ont déjà été étudiées pour ce type de puces: les techniques DTM (Dynamic Thermal Management) ont montré qu'elles ne sont pas encore assez convaincantes pour ces architectures 3D, et les techniques DTM (vues précédemment pour les puces 2D) ont une efficacité avec les puces 3D qui doit encore être démontrée par l'expérience.
Le travail fait par Young Jin Park et son équipe[7] montre comment les techniques DFS permettent de gérer le problème thermique pour les processeurs multi-cœurs ayant une architecture en 3D.
Améliorations apportées pour la gestion des ressources
Dans la majorité des systèmes d’exploitation actuel, les différents algorithmes d'ordonnancement tentent de repartir de manière homogène les différents processus dans les ressources disponibles afin d’équilibrer le temps CPU sur chacun des cœurs et ainsi minimiser l’utilisation au ralentit des différents cœurs[8]. Ces algorithmes considère donc les différents cœurs comme des processeurs à part entière. Or, il existe différentes études qui ont montré que la durée d’exécution d’un même thread pouvait varier en fonction du cœur sur lequel il est exécuté. Cela est particulièrement vrai si plusieurs cœurs partagent le même cache dernier niveau (LLC)[9]. L’amélioration des performances des microprocesseurs pour les systèmes multi-cœurs passent donc par une amélioration principale : Une meilleur gestion des threads et des données partagées entre chacun d’eux afin de tiré profit des différents niveaux de caches présent sur les microprocesseurs.
Ordonnancement et gestion des caches
L’ordonnanceur est la partie du système d’exploitation qui choisit quel processus va être exécuté par le CPU à un instant donné. La plupart des systèmes d'exploitation donnent aux applications un choix entre deux configurations de partage de la mémoire globale: un espace d'adressage unique partagé par tous les cœurs ou d'un espace d'adressage séparé par cœur. Dans les deux cas, la tendance actuelle est de considérer chaque cœur comme un processeur séparé qui peut partager ou non une zone mémoire. Cette technique empêche de tirer profit d’un certain nombre de solutions matérielles proposées par les différents constructeurs tel que le partage d’informations entre les différents caches des cœurs[9].
On observe cependant sur les systèmes AMD 16 cœurs une différence de vitesse entre un accès au cache et un accès à la mémoire centrale (RAM) d'un facteur de 100. De plus, ce facteur est susceptible de croître avec le nombre de cœurs. Les tests sur les processeurs Intel Xeon montrent un ratio semblable[10]. Le défaut de cache se caractérise par une information ou une instruction non présente dans le cache du cœur ce qui oblige le processeur à aller chercher l’information dans la mémoire centrale de l'ordinateur.
Un second point d’altération des performances peut être le partage des lignes de caches entre les différents cœurs. En cas de section critique, le code va verrouiller l'accès à certaines ligne de cache. Même s'il ne s’agit que d’instructions cela peut faire baisser le rendement car cela provoque des défauts de caches. Ces effets sont d’autant plus importants quand il s’agit de requêtes sur des données ou que le nombre de cœurs est élevé puisque le coût d'accès à un cache éloigné augmente[10].
Une première optimisation à apporter aux ordonnanceurs consiste donc à gérer le placement des threads sur les différents cœurs en fonction des ressources que ces derniers ont à partager[11] . Pour résoudre ce problème une des méthodes les plus connues est l’algorithme SDC (Stack Distance Competition) proposé par Chandra[12]. Cet algorithme permet de déterminer la façon dont les threads vont interagir les uns avec les autres et ainsi prédire s'il est utile de les faire partager le même cache. Le modèle SDC va donc essayer de construire une nouvelle pile de profil distante qui sera la fusion des distantes piles de profils threads qui s'exécutent simultanément.Pour ce faire, chaque profil est affecté à un pointeur courant qui est initialisé au premier compteur de la pile distante. À chaque itération, tous les compteurs pointé par le pointeur courant de tous les profils individuels sont comparés. Le profil avec la plus grande valeur est choisi comme gagnant.
Un algorithme de fusion sélectionne itérativement une pile distante à partir du profil «gagnant» pour être incluse dans le profil fusionnée. Le compteur du vainqueur est alors copié dans le profil fusionné, et son pointeur courant est avancé.
Après la dernière itération, l'espace de cache efficace pour chaque thread est calculé proportionnellement au nombre de compteurs de la pile distante qui sont inclus dans le profil fusionné.
Le modèle de concurrence de pile distante est intuitif car il suppose que plus la fréquence de réutilisation est importante, plus l'espace cache est efficace[11].
Cet algorithme permet d’avoir un point de référence pour les algorithmes d’ordonnancement sur les systèmes multi-cœurs mais est difficilement mis en œuvre en temps réel car il nécessite de connaitre à l’avance les instructions et les données partagées de chaque thread.Le système d’exploitation comme un système distribué
Une seconde approche afin d’optimiser les performances sur les systèmes multi-cœurs est de les considérés comme des systèmes distribuées. L’apparition de ces systèmes a été poussé pour résoudre trois problématiques majeurs : l’hétérogénéité des nœuds, les changements dynamiques en raison de défaillances partielles et la latence. Les ordinateurs moderne répondent également à ces différentes contraintes. Répondre à ces différentes contrainte revient à remettre en cause la façon dont sont conçu les systèmes d’exploitation actuel[13].
Les nœuds dans un système distribué tendent à aller et venir à la suite de la modification de leur approvisionnement, d’anomalies réseaux etc. Jusqu’à présent, on pouvait considéré un ordinateur comme un système centralisé. Tous les processeurs partageaient la mémoire centrale (RAM) et les architectures des différents processeurs puis cœurs de calcul étaient sensiblement identique. Or, on observe sur les feuilles de routes des différents constructeurs des puces possédant plusieurs cœurs avec, pour chacun d’entre eux, différents jeux d’instructions. Cette dynamicité ce retrouve donc également dans nos ordinateurs[13]. De plus en plus de périphériques sont connétables à chaud et même dans certain cas la mémoire et les processeurs. La gestion accrues des ressources et de l’énergie permet également de faire varié l’état de puissance de certains composants ce qui peut avoir des implications sur le fonctionnement de l’OS. Par exemple, si un contrôleur de bus est mis hors tension, tous les périphériques sur ce bus deviennent inaccessibles. Si un cœur de processeur est suspendu, tous les processus sur ce cœur sont inaccessibles jusqu'à il reprend, à moins qu'ils ne sont migrés[14]. Tous cela doit pouvoir être gérer par le noyau du système d’exploitation d'où l’approche inspirée des systèmes distribués.
Dans un système moderne, le partage de données entre les caches équivaut à une série d’appel RPC (Remote Procedure Call) synchrone pour aller chercher les lignes de cache à distance. Pour une structure de données complexes, cela signifie beaucoup d'allers-retours, dont le rendement est limité par le temps de latence et par la bande passante de l'interconnexion. Dans les systèmes distribués, les appels RPC sont réduits par une opération d'encodage de haut niveau plus compacte; à la limite, cela devient un appel RPC unique. Lorsque la communication est chère (la latence ou la bande passante), il est plus efficace d'envoyer un seul message encoder pour une opération plutôt que d’accéder aux données à distance[14]. En outre, l'utilisation du passage de messages plutôt que de données partagées facilite l'interopérabilité entre les processeurs hétérogènes. Il y a bien longtemps, Lauer et Needham ont mis en avant l'équivalence entre la mémoire partagée et de passage de messages dans les systèmes d'exploitation. Depuis plusieurs études ont révélé qu’il était plus efficace d’utiliser le passage de message d’abord pour les systèmes multi-processeurs, puis plus récemment, pour les processeurs multi-cœurs.Une seconde optimisation consiste à utiliser la réplication des données. Cela existe déjà dans le noyau Linux par exemple, avec l’utilisation de la "translation lookaside buffer" (TLB). La TLB est une mémoire cache du processeur utilisé par l'unité de gestion mémoire (MMU) dans le but d'accélérer la traduction des adresses virtuelles en adresses physiques. Cependant, pour pouvoir tirer profit de cette optimisation, le code OS devrait être écrit comme s'il consulté une réplique locale des données plutôt qu’une copie partagée[14].
Le principal impact sur les clients, c'est qu'ils invoquent maintenant un protocole d'accord (proposer une modification de l'état du système, et plus tard recevoir une notification accord ou non) plutôt que de modifier des données dans une section critique. Le changement de modèle est important car il fournit une manière uniforme pour synchroniser l'état à travers des processeurs hétérogènes qui ne peuvent pas partager la mémoire de manière cohérente[14].
Conclusion
Depuis l’arrivée des premiers microprocesseurs double cœurs en 2005, le nombre de cœurs ne cesse d’augmenter dans l’objectif d’améliorer toujours plus la puissance des ordinateurs. On observe cependant que cette technique qui consiste à augmenter le nombre de cœurs au sein de la puce afin d'en améliorer les performances a elle-même atteint certaines limites tant au niveau du hardware que du software.
Afin de repousser ces limites, les chercheurs et ingénieurs proposent différentes solutions:
- Michael Kadin et Sherief Reda ont montré par leur travail[15] que l'utilisation de modélisations mathématiques peuvent aider à augmenter les performances d'un système avec des cœurs au repos. En effet, leur méthode permet de redistribuer les charges de travail en ajustant les fréquences des cœurs tout en s'assurant de ne pas dépasser les températures limites tolérées par eux-mêmes;
- le travail fait par Young Jin Park et son équipe[4] montre comment les techniques DFS permettent de gérer le problème thermique pour les processeurs multi-cœurs ayant une architecture en 3D;
- beaucoup de chercheurs tentent de revoir revoir les politiques d'ordonnancements afin de tenir compte de la communication entre les cœurs et des différents niveaux de caches, et à l'avenir des spécificité de chacun des cœurs ;
- il faut également repenser la façon dont OS sont conçus afin de mieux appréhender les nouvelles normes technologiques qui voient le jour.
Enfin, pour conclure, une perspective d'avenir dans le monde des microprocesseurs serait d'utiliser du graphène en lieu et place du silicium. Le graphène offre de multiples ouvertures dans beaucoup de domaines. C'est tout d'abord le matériau le plus fin du monde (0,6 nanomètre d'épaisseur), 200 fois plus résistant que l'acier et pourtant souple. De plus, il s'agit d'un aussi bon conducteur que le cuivre et qui ne chauffe pas lorsque il est traversé par de l'électricité. Enfin, du point de vue optique, il est transparent. Ainsi, grâce au graphène, une nouvelle génération de transistors ultra rapides aux dimensions nanométriques a été créée en laboratoire par Manuela Melucci et son équipe[16].
Annexes
Références
- Kadin, 2008, page 463
- von Behren, 2003, page 1
- Ousterhout, 1996, page 1
- Park, 2010, page 69
- Kadin, 2008, page 464
- Kadin, 2008, page 470
- Park, 2010, page 73
- Knauerhase, 2008, page 1
- zhuravlev, 2010, page 1
- Corey,page 1-10, 2008
- zhuravlev, 2010, page 4
- Chandra, 2005
- Baumann, page 1, 2009
- Baumann, page 2, 2009
- Kadin, 2008, page 463 - 470
- Melucci, 2010
Bibliographie
- (en) Manuela Melucci, Emanuele Treossi, Luca Ortolani, Giuliano Giambastiani, Vittorio Morandi, Philipp Klar, Cinzia Casiraghi, Paolo Samorì et Vincenzo Palermo, « Facile covalent functionalization of graphene oxide using microwaves: bottom-up development of functional graphitic materials », dans J. Mater. Chem. (2010), 2010 (ISSN 9052-9060) [texte intégral]
- (en) M. Kadin et S. Reda, « Frequency and voltage planning for multi-core processors under thermal constraints », dans Computer Design, 2008. ICCD 2008. IEEE International Conference on, 12-15 octobre 2008, p. 463-470 (ISSN 1063-6404) [texte intégral [PDF]]
- (en) Dongkeun Oh, Nam Sung Kim, Charlie Chung Ping Chen, Azadeh Davoodi et Yu Hen Hu, « Runtime temperature-based power estimation for optimizing throughput of thermal-constrained multi-core processors », dans Design Automation Conference (ASP-DAC), 2010 15th Asia and South Pacific, 25 février 2010, p. 593 [texte intégral [PDF]]
- (en) Michael B. Healy, Hsien-Hsin S. Lee, Gabriel H. Loh et Sung Kyu Lim, « Thermal optimization in multi-granularity multi-core floorplanning », dans Design Automation Conference, 2009. ASP-DAC 2009. Asia and South Pacific, 27 février 2009, p. 43 [texte intégral [PDF]]
- (en) Young Jin Park, Min Zeng, Byeong-seok Lee, Jeong-A Lee, Seung Gu Kang et Cheol Hong Kim, « Thermal Analysis for 3D Multi-core Processors with Dynamic Frequency Scaling », dans Computer and Information Science (ICIS), 2010 IEEE/ACIS 9th International Conference on, 30 septembre 2010, p. 69 [texte intégral [PDF]]
- (en) R. Jayaseelan et T. Mitra, « A hybrid local-global approach for multi-core thermal management », dans Computer-Aided Design - Digest of Technical Papers, 2009. ICCAD 2009. IEEE/ACM International Conference on, 28 décembre 2009, p. 314 [texte intégral [PDF]]
- (en) Shekhar Borkar, « Thousand Core Chips—A Technology Perspective », dans Intel Corp, Microprocessor Technology Lab, 2007, p. 1-4
- (en) Chang-Burm Cho, James Poe, Tao Li et Jingling Yuan, « Accurate, scalable and informative design space exploration for large and sophisticated multi-core oriented architectures », dans Modeling, Analysis & Simulation of Computer and Telecommunication Systems, 2009. MASCOTS '09. IEEE International Symposium on, 28 décembre 2009, p. 1 [texte intégral [PDF]]
- (en) P.P. Gelsinger, « Microprocessors for the new millennium: Challenges, opportunities, and new frontiers », dans Solid-State Circuits Conference, 2001. Digest of Technical Papers. ISSCC. 2001 IEEE International, 07 août 2002, p. 22 [texte intégral [PDF]]
- Erreur dans la syntaxe du modèle Article(en) Vivek De et Shekhar Borkar, « Technology and Design Challenges for Low Power and High Performance », dans , 1999
- (en) Long Zheng, Mianxiong Dong, Kaoru Ota, Huakang Li, Song Guo et Minyi Guo, « Exploring the Limits of Tag Reduction for Energy Saving on a Multi-core Processor », dans Parallel Processing Workshops (ICPPW), 2010 39th International Conference on, 11 octobre 2010, p. 104 (ISSN 1530-2016) [texte intégral [PDF]]
- (en) Gerhard Wellein, G. Hager, T. Zeiser et M. Meier, « Architecture and performance of multi-/many core systems », dans ASIM – Workshop – Erlangen, 19 février 2008, p. 1 [texte intégral [PDF]]
- (en) Veronica Gil-Costa, Ricardo J. Barrientos, Mauricio Marin et Carolina Bonacic, « Scheduling Metric-Space Queries Processing on Multi-Core Processors », dans Parallel, Distributed and Network-Based Processing (PDP), 2010 18th Euromicro International Conference on, 22 avril 2010, p. 187 [texte intégral [PDF]]
- (en) Rainer Dömer, « Computer-aided recoding for multi-core systems », dans Design Automation Conference (ASP-DAC), 2010 15th Asia and South Pacific, 25 février 2010, p. 713 [texte intégral [PDF]]
- (en) Bingbing Xia, Fei Qiao, Huazhong Yang et Hui Wang, « A fault-tolerant structure for reliable multi-core systems based on hardware-software co-design », dans Quality Electronic Design (ISQED), 2010 11th International Symposium on, 15 avril 2010, p. 191 (ISSN 1948-3287) [texte intégral [PDF]]
- (en) Calin Cascaval, Colin Blundell, Maged M. Michael, Harold W. Cain, Peng Wu, Stefanie Chiras et Siddhartha Chatterjee, « Software transactional memory: Why is it only a research toy ? », dans ACM Queue 6. n°5, 2008, p. 46-58
- (en) John Ousterhout, « Why threads are a bad idea ? », dans 1996 USENIX Technical Conference, 25 janvier 1996, p. 1 [texte intégral]
- (en) Rob von Behren, Jeremy Condit et Eric Brewer, « Why Events Are A Bad Idea (for high-concurrency servers) ? », dans USENIX Association, 18–21 mai 2003, p. 1 [texte intégral [PDF]]
- (en) Silas Boyd-Wickizer, Haibo Chen, Rong chen, Yandong Mao, Frans Kaashoek, Robert Morris, Aleksey Pesterev, Lex Stein, Ming Wu, Yuehua Dai, Yang Zhang et Zheng Zhang, « Corey: An Operating System for Many Cores », dans 8th USENIX Symposium on Operating Systems Design and Implementation, 2008, p. 1-14 [texte intégral [PDF]]
- (en) Andrew Baumann, Simon Peter, Timothy Roscoe, Adrian Schüpbach, Paul Barhamt, Akhilesh Singhania et Rebecca Isaacst, « Your computer is already a distributed system. Why isn’t your OS? », dans workshop on Hot Topics in Operating Systems, 2009 [texte intégral]
- (en) Sergey Zhuravlev, Sergey Blagodurov et Alexandra Fedorova, « Addressing Shared Resource Contention in Multicore Processors via Scheduling », dans ASPLOS'10, 2010
- Erreur dans la syntaxe du modèle Article(en) Rob Knauerhase, Paul Brett, Barbara Hohlt, Tong Li et Scott Hahn, « Using OS Obsercations to improve perfomance in multicore systems », dans , 2008
- (en) Dhruba Chandra, Fei Guo, Seongbeom Kim et Yan Solihin, « Predicting Inter-Thread Cache Contention on a Chip Multi-Processor Architecture », dans HPCA ’05: Proceedings of the 11th International Symposium on High-Performance Computer Architecture, 2005
- (en) James Reinders, Intel threading building blocks, 2007 éditeur=O'Reilly (ISBN 0596514808), « Thinking Parallel »


Wikimedia Foundation. 2010.