- Jaro-Winkler
-
Distance de Jaro-Winkler
La distance de Jaro-Winkler mesure la similarité entre deux chaînes de caractères. Il s'agit d'une variante proposée en 1999 par William E. Winkler, découlant de la distance de Jaro (1989, Matthew A. Jaro) qui est principalement utilisée dans la détection de doublons.
Plus la distance de Jaro-Winkler entre deux chaînes est élevée, plus elles sont similaires. Cette mesure est particulièrement adaptée au traitement de chaînes courtes comme des noms ou des mots de passe. Le résultat est normalisé de façon à avoir une mesure entre 0 et 1, le zéro représentant l'absence de similarité.
Sommaire
Distance de Jaro
La distance de Jaro entre chaînes s1 et s2 est définie par :
où:
- m est le nombre de caractères correspondants (voir ci-dessous);
- t est le nombre de transpositions (voir ci-dessous).
Deux caractères identiques de s1 et de s2 sont considérés comme correspondants si leur éloignement (i.e. la différence entre leurs positions dans leurs chaînes respectives) ne dépasse pas :
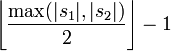 .
.
Le nombre de transpositions est obtenu en comparant le i-ème caractère correspondant de s1 avec le i-ème caractère correspondant de s2. Le nombre de fois où ces caractères sont différents, divisé par deux, donne le nombre de transpositions.
Distance de Jaro-Winkler
La méthode introduite par Winkler utilise un coefficient de préfixe p qui favorise les chaînes commençant par un préfixe de longueur
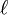 (avec
(avec 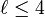 ). En considérant deux chaînes s1 et s2, leur distance de Jaro-Winkler dw est :
). En considérant deux chaînes s1 et s2, leur distance de Jaro-Winkler dw est :où :
- dj est la distance de Jaro entre s1 et s2
- est la longueur du préfixe commun (maximum 4 caractères)
- p est un coefficient qui permet de favoriser les chaînes avec un préfixe commun. Winkler propose pour valeur p = 0.1
Exemples
Soit deux chaînes s1 MARTHA et s2 MARHTA. La table de correspondance est :
M A R T H A M 1 0 0 0 0 0 A 0 1 0 0 0 0 R 0 0 1 0 0 0 H 0 0 0 0 1 0 T 0 0 0 1 0 0 A 0 0 0 0 0 1 - m = 6 (nombre de 1 dans la table)
- | s1 | = 6
- | s2 | = 6
- Les caractères correspondants sont {M,A,R,T,H,A} pour s1 et {M,A,R,H,T,A} pour s2. En considérant ces ensembles ordonnés, on a donc 2 couples (T/H et H/T) de caractères correspondants différents, soit deux demi-transpositions. D'où
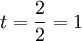
La distance de Jaro est :
La distance de Jaro-Winkler avec p = 0.1 avec un préfixe de longueur
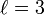 devient
devientAvec les chaînes s1 DWAYNE et s2 DUANE on trouve :
- m = 4
- | s1 | = 6
- | s2 | = 5
- t = 0
La distance de Jaro est :
Celle de Jaro-Winkler avec
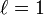 :
:Avec les chaînes s1 DIXON et s2 DICKSONX, on obtient :
D I X O N D 1 0 0 0 0 I 0 1 0 0 0 C 0 0 0 0 0 K 0 0 0 0 0 S 0 0 0 0 0 O 0 0 0 1 0 N 0 0 0 0 1 X 0 0 0 0 0 On calcule l'éloignement maximum pour le critère de correspondance
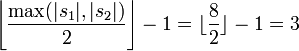 .
.
- m = 4 (les deux X ne correspondent pas, car ils sont éloignés de plus de 3 caractères)
- | s1 | = 5
- | s2 | = 8
- t = 0
La distance de Jaro :
La distance de Jaro-Winkler avec
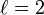 :
:Références
- Jaro, M. A., « Advances in record linking methodology as applied to the 1985 census of Tampa Florida », dans Journal of the American Statistical Society, vol. 84, no 406, 1989, p. 414-420
- Jaro, M. A., « Probabilistic linkage of large public health data file », dans Statistics in Medicine, vol. 14, 1995, p. 491-498 [texte intégral]
- Winkler, W. E., « The state of record linkage and current research problems », dans Statistics of Income Division, Internal Revenue Service Publication R99/04, 1999 [texte intégral]
- Winkler, W. E., « Overview of Record Linkage and Current Research Directions », dans Research Report Series, RRS, 2006 [texte intégral]
Liens externes
- (en) Implémentation Opensource en Java et .NET
- (en) Implémentation originale en C
- (fr) Implémentation en Delphi
- (fr) Implémentation simple en C
 Portail de l’informatique
Portail de l’informatique
Catégorie : Algorithme sur les chaînes de caractères
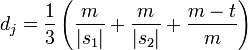
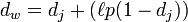
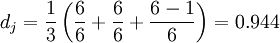
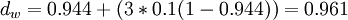
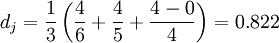
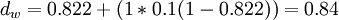
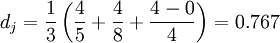
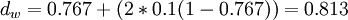
Wikimedia Foundation. 2010.