- Système de gestion de base de données
-
En informatique un système de gestion de base de données (abr. SGBD) est un logiciel système destiné à stocker et à partager des informations dans une base de données, en garantissant la qualité, la pérennité et la confidentialité des informations, tout en cachant la complexité des opérations.
Un SGBD (en anglais DBMS pour database management system) permet d'inscrire, de retrouver, de modifier, de trier, de transformer ou d'imprimer les informations de la base de données. Il permet d'effectuer des compte-rendus des informations enregistrées et comporte des mécanismes pour assurer la cohérence des informations, éviter des pertes d'informations due à des pannes, assurer la confidentialité et permettre son utilisation par d'autres logiciels[1]. Selon le modèle, le SGBD peut comporter une simple interface graphique jusqu'à des langages de programmation sophistiqués[1].
Les systèmes de gestion de base de données sont des logiciels universels, indépendants de l'usage qui est fait des bases de données[2]. Ils sont utilisés pour de nombreuses applications informatiques, notamment les guichets automatique bancaires, les logiciels de réservation, les bibliothèques numériques les logiciels d'inventaire, les progiciels de gestion intégrés ou la plupart des blogs et sites web. Il existe de nombreux systèmes de gestion de base de données. En 2008 les trois produits IBM DB2, Oracle Database et Microsoft SQL Server occupent 80 % du marché des SGBD relationnels[3].
Les SGBD sont souvent utilisés par d'autres logiciels ainsi que les administrateurs ou les développeurs. Ils peuvent être sous forme de composant logiciel, de serveur, de logiciel applicatif ou d'environnement de programmation.
En 2011 la majorité des SGBD du marché manipulent des bases de données relationnelles.
Sommaire
But visé
Les SGBD sont les logiciels intermédiaires entre les utilisateurs et les bases de données. Une base de données est un magasin d'information composé de plusieurs fichiers manipulés exclusivement par le SGBD. Ce dernier cache la complexité de manipulation des structures de la base de données et met à disposition une vue synthétique du contenu[4].
L'ensemble SGBD et base de données est destiné à permettre le stockage d'informations d'une manière qui offre de nombreux avantages par rapport à un enregistrement conventionnel dans des fichiers. Il permet d'obtenir et de modifier rapidement des informations, de les partager entre plusieurs usagers. Il garantit l'absence de redondance, l'intégrité, la confidentialité et la pérennité des informations tout en donnant des moyens d'éviter les éventuels conflits de modifications et en cachant les détails du format de fichier des bases de données[1].
Les informations sont enregistrées sous forme de données: des suites de bits sans signification qui sont la représentation de renseignements bruts (lettres, nombres, couleurs, formes,...). Le SGBD comporte différents mécanismes destinés à retrouver rapidement les données et les convertir en vue d'obtenir des informations qui ont un sens[1].
- à l'aide du SGBD plusieurs usagers et plusieurs logiciels peuvent accéder simultanément aux informations. Le SGBD effectue les vérifications pour assurer qu'aucune personne non autorisée n'ait accès à des informations confidentielles contenues dans la base de données, il arbitre les collisions lorsqu'il y a plusieurs modifications simultanées de la même information et comporte des mécanismes en vue d'éviter des pertes d'informations suite à une panne[1];
- la redondance est la présence de plusieurs copies de la même information - dont la modification peut amener à des incohérences, c'est-à-dire que les différentes copies ne correspondent plus. Le SGBD vérifie - voire refuse - la présence de redondances. Le SGBD effectue également sur demande des vérifications pour assurer que les informations qui sont introduites sont correctes: que les valeurs sont dans les limites admises, que leur format est correct et que les informations sont cohérences par rapport à ce qui se trouve déjà dans la base de données[1];
- les informations sont typiquement manipulées par un logiciel applicatif qui fait appel aux services du SGBD pour manipuler la base de données. Alors qu'un logiciel applicatif qui manipule un fichier tient compte du format de données de ce fichier, un logiciel qui manipule une base de données par l'intermédiaire d'un SGBD n'a pas connaissance du format de la base de données, les informations sont présentées par le SGBD sous une forme qui cache les détails du format des fichiers dans lesquels elles sont enregistrées[1].
Les SGBD contemporains sont des logiciels sophistiqués qui nécessitent du personnel hautement qualifié, et leur utilisation entraine souvent une augmentation substantielle des coûts liés aux licences et à la formation[4].
Fonctionnalités
Un SGBD permet d'enregistrer des informations, puis les rechercher, les modifier et créer automatiquement des compte-rendus (anglais report) du contenu de la base de données. Il permet de spécifier les types de données, la structure des informations contenues dans la base de données, ainsi que des règles de cohérence telles que l'absence de redondance[5].
Les caractéristiques des informations enregistrées dans la base de données, ainsi que les relations, les règles de cohérence et les listes de contrôle d'accès sont enregistrées dans un catalogue qui se trouve à l'intérieur de la base de données et qui est manipulé par le SGBD[5].
Les opérations de recherche et de manipulation des informations, ainsi que la définition des caractéristiques des informations, des règles de cohérences et des autorisations d'accès peuvent être exprimés sous forme de requêtes (anglais query) dans un langage informatique reconnu par le SGBD[5]. SQL est le langage informatique le plus populaire[6],[7], c'est un langage normalisé de manipulation des bases de données[8]. Il existe de nombreux autres langages comme le Databasic de Charles Bachman[9], Dataflex, dBase ou xBaseScript (etc.).
Les bases de données peuvent être d'une taille de plusieurs téraoctets; une taille supérieure à la place disponible dans la mémoire centrale de l'ordinateur. Les bases de données sont enregistrées sur disque dur, ces derniers ont une capacité supérieure, mais sont moins rapides, et le SGBD est équipé de mécanismes visant à accélérer les opérations[5]. Les SGBD contemporains enregistrent non seulement les données, mais également leur description, des formulaires, la définition des compte-rendus, les règles de cohérence, des procédures; ils permettent le stockage de vidéos et d'images. Le SGBD manipule les structures complexes nécessaire à la conservation de ces informations[4].
Les SGBD sont équipés de mécanismes qui effectuent des vérifications à l'insu de l'utilisateur, en vue d'assurer la réussite des transactions, éviter des problèmes dus à la concurrence et assurer la sécurité des données[4] :
- transactions : une transaction est une opération unitaire qui transforme le contenu de la base de données d'un état A vers un état B. La transformation peut nécessiter plusieurs modifications du contenu de la base de données. Le SGBD évite qu'il existe des états intermédiaires entre A et B en garantissant que les modifications sont effectuées complètement ou pas du tout. En cas de panne survenue durant des opérations de modification de la base de données, le SGBD remet la base de données dans l'état ou elle était au début de la transaction (état A)[5] ;
- concurrence : la base de données peut être manipulées simultanément par plusieurs personnes, et le contrôle de la concurrence vérifie que ces manipulations n'aboutissent pas à des incohérences. Par exemple dans un logiciel de réservation, le SGBD vérifie que chaque place est réservée au maximum par une personne, même si des réservation sont effectuées simultanément[5] ;
- sécurité des données : le choix de permettre ou d'interdire l'accès à des informations est donné par des listes de contrôle d'accès, et des mécanismes du SGBD empêchent des personnes non autorisées de lire ou de modifier des informations pour lesquelles l'accès ne leur a pas été agréé[5].
Typologie
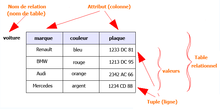 modèle de données relationnel
modèle de données relationnel
Selon leur construction et les possibilités qu'ils offrent les SGBD peuvent être dit relationnels, orienté objet, objet-relationnel. Ils peuvent être distribués, centralisés ou embarqués et peuvent être spatials. Ils se différencient également par la taille des bases de données qu'ils peuvent manipuler[10]. En 2010 la majorité des SGBD sont de type relationnel: ils manipulent des bases de données conformément au modèle de données relationnel[11].
- relationnel: Selon ce modèle, les informations sont placées dans des tables avec lignes et colonnes et n'importe quelle information contenue dans la base de données peut être retrouvée à l'aide du nom de la table, du nom de la colonne et de la clé primaire. Le modèle relationnel est destiné à assurer l'indépendance des données et à offrir les bases pour contrôler la cohérence et éviter la redondance. Il permet de manipuler les données comme des ensembles en effectuant des opérations de la théorie des ensembles. Les règles de cohérence qui s'appliquent aux bases de données relationnelles sont l'absence de redondance ou de nul des clés primaires, et l'intégrité référentielle[11] ;
- orienté objet et objet-relationnel : Les SGBD orientés objet sont un sujet de recherche depuis 1980, lorsque sont apparus les premiers langages de programmation orientée objet. Ils sont destinés à offrir les fonctionnalités des SGBD à des langages orientés objet et permettre le stockage persistant des objets. Les objets sont manipulés en utilisant les possibilités natives des langages orientés objet et une interface de programmation permet d'exploiter les fonctionnalités du SGBD. Celui-ci est équipé des mécanismes nécessaires pour permettre l'utilisation des possibilités d'encapsulation, d'héritage et de polymorphisme des langages de programmation orientée objet[12],[13]. Les SGBD objet-relationnel offrent à la fois les possibilités des SGBD orientés objet et ceux des SGBD relationnels[14].
- centralisé ou distribué : Un SGBD est dit centralisé lorsque le logiciel contrôle l'accès à une base de données placée sur un ordinateur unique. Il est dit distribué lorsqu'il contrôle l'accès à des données qui sont dispersées entre plusieurs ordinateurs. Dans cette construction, un logiciel est placé sur chacun des ordinateurs, et les différents ordinateurs utilisent des moyens de communication pour coordonner les opérations. Le fait que les informations sont dispersées est caché à l'utilisateur, et celles-ci sont présentées comme si elles se trouvaient à une seule place[15] ;
- embarqué: Une base de données embarquée (anglais embedded) est un SGBD sous forme de composant logiciel qui peut être incorporé dans un logiciel applicatif. Contrairement à un SGBD client-serveur dans lesquel un processus traite les requêtes, un modèle embarqué se compose de bibliothèques logicielles liées par liaison dynamique avec le logiciel qui utilise le SGBD. Dans ce type de SGBD, la base de données est souvent composée d'un fichier unique dont le format est identique quelles que soient les caractéristiques de l'ordinateur utilisé. Bien que le SGBD offre de nombreux avantages par rapport à un enregistrement sur fichier, ces derniers sont souvent préférés aux SGBD, qui ont la réputation d'être des logiciels lourds, encombrants et compliqués à installer[16].
- spatial: Les applications informatiques telles que les système d'information géographiques et les outils de conception assistée par ordinateur utilisent des SGBD spatial. Ce type de logiciel permet le stockage d'informations géométriques telles que des points, des lignes, des surfaces et des volumes. Ils comportent des fonctions permettant de retrouver une information sur la base de caractéristiques géométriques telles que les coordonnées ou la dimension. Le langage de requête du SGBD permet la manipulation d'informations de géométrie tels que lignes, point ou polygones, le SGBD met en œuvre les algorithmes et les structures de fichiers nécessaire[2] ;
Taille des bases de données
Les différents SGBD sur le marché se différencient par le périmètre d'utilisation des bases de données : Le périmètre influence le nombre d'utilisateurs simultanés, la taille des bases de données, la ou les emplacements, et la puissance de calcul nécessaire. Certains SGBD supportent de très grandes bases de données, et nécessitent des ordinateurs puissants et très couteux. D'autres SGBD fonctionnent sur des ordinateurs personnels bon marché, avec des limites quand à la taille des bases de données et la puissance de calcul[10],[4]. On peut les classer en :
- SGBD personnels : ces produits sont beaucoup plus simples que les modèles pour les entreprises du fait qu'ils sont concus pour servir un seul utilisateur à la fois; Lorsqu'un deuxième utilisateur essaye d'accéder à la base de données, il doit attendre que le premier ait terminé. Ces SGBD sont parfois installés sur des ordinateurs personnels pour des bases de données dites de bureau (anglais desktop database). Les bases de données des applications personnelles sont plus petites[4] ;
- les SGBD de groupe : les SGBD de groupe et d'enteprise peuvent être utilisés par plusieurs usagers simultanément. Ils sont dit de groupe lorsque le nombre d'usagers est relativement restreint (50 à 100). Aujourd'hui les modèles de groupe sont les plus populaires dans les petites et moyennes institutions[10],[4] ;
- SGBD d'entreprise : les premiers SGBD sont apparus en 1960. Les ordinateurs de cette époque était très grands et très cher. et les SGBD étaient tous de taille entreprise: puissants, robustes et gourmands en matériel. Avec l'amélioration technologique, les SGBD d'enteprise sont devenus plus puissants, sont capable de manipuler de grande quantités d'informations et peuvent être utilisées par des milliers d'utilisateurs simultanément[10] ;
- Internet : l'apparition dans les années 2000 de services Internet de grande audience a nécessité des moyens techniques adaptés à des besoins sans précédents en terme de nombre d'utilisateurs et de quantité d'informations[17]. Prévus pour la répartition de charge (anglais load balancing), de nouveaux SGBD dits NoSQL ont fait le compromis de ne pas mettre en œuvre certaines fonctionalités classiques des SGBD en vue d'obtenir la puissance de calcul et la scalabilité nécessaire aux populaires services web de e-commerce, de recherche ou de réseau social[18].
Histoire
Jusqu'en 1960 les informations étaient enregistrées dans des fichiers manipulées par les logiciels applicatifs[2]. L'idée des bases de données a été lancée en 1960 dans le cadre du programme Apollo. Le but était de créer un dispositif informatique destiné à enregistrer les nombreuses informations en rapport avec le programme spatial, en vue de se poser sur la lune avant la fin de la décennie[11]. C'est dans ce but que IBM, conjointement avec Rockwell met sur le marché le logiciel Information Management System (IMS). Avec ce SGBD, les informations sont enregistrées dans des bases de données organisées de manière hiérarchique[2].
A la même époque General Electric, avec l'aide de Charles Bachman met sur le marché le logiciel Integrated Data Store. Avec ce SGBD les informations sont enregistrées dans des bases de données organisées selon un modèle réseau, ce qui permet d'enregistrer des informations ayant une organisation plus complexe que le modèle hiérarchique[2].
En 1965 Dick PICK développe le système d'exploitation Pick, qui comporte un SGBD et le langage Databasic de Charles Bachman[19]. En 2002 la technologie de Pick est utilisée dans des produits contemporains tels que JBase [20].
En 1967 le consortium CODASYL forme un groupe de travail, le database task group abr. DBTG, qui travaille à la normalisation de deux langages informatique en rapport avec les bases de données: le DML et le DDL[2].
Les organisations hiérarchiques et réseau des années 1960 manquaient d'indépendance vis-à-vis du format des fichiers, ils rendaient complexe la manipulation des données et il leur manquait une base théorique. En 1970 Edgar Frank Codd, employé de IBM publie le livre A relational model of data for large shared data banks, un ouvrage qui présente les fondations théoriques de l'organisation relationnelle[2]. Sur la base des travaux de E.F Codd, IBM développe le SGBD System R, qui sera mis sur le marché à la fin des années 1970. Il est destiné à démontrer la faisabilité d'un SGBD relationnel. Le langage informatique propre à ce SGBD est le Structured Query Language (abr. SQL), défini par IBM et destiné à la manipulation des bases de données relationnelles[11].
Charles Bachman reçoit le prix Turing en 1973 pour ces contributions à la technologie des bases de données et Edgar Frank Codd reçoit le prix Turing en 1981 pour les mêmes raisons[21].
En 1978 ANSI publie la description de l'architecture Ansi/Sparc qui sert de modèle de référence en rapport avec l'indépendance des données des SGBD[2].
Les deux SGBD ténor du marché de 2010 que sont IBM DB2 et Oracle Database ont été mis sur le marché en 1979 et sont tout deux basés sur le modèle relationnel. La même année le langage SQL est normalisé par ISO[2].
Les moteur de recherche et les datawarehouse sont des applications informatiques apparues dans les années 1990, qui ont influencé le marché des SGBD. Les moteurs de recherche ont nécessité le traitement d'informations non structurées et écrites en langage naturel. Et les datawarehouse ont nécessité la collecte et la consolidation de très grande quantités d'informations en vue de réaliser des tableaux de synthèse[21].
Les modèles d'organisation orienté objet et objet-relationnel sont apparus dans les années 1990[2]. Les premiers SGBD objet-relationnel ont été Postgres, Informix et Oracle Database en 1995. Le standard relatif au langage SQL a été modifié en 1999 pour pouvoir s'appliquer à ce type de SGBD[22].
Construction et fonctionnement
Un SGBD est composé de nombreux programmes, parmi lesquels le moteur, le catalogue, le processeur de requêtes, le langage de commande et des outils[23] :
- le moteur de base de données est le cœur du SGBD, il manipule les fichiers de la base de données, transmet les données de et vers les autres programmes, et vérifie la cohérence et l'intégrité des données[23] ;
- un programme manipule le catalogue : le magasin qui contient la description de l'organisation de la base de données, les listes de contrôle d'accès, le nom des personnes autorisées à manipuler la base de données et la description des règles de cohérence (contraintes)[23]. Selon les modèles de SGBD ces informations peuvent être modifiées en utilisant le langage de commande, ou alors à l'aide d'une interface graphique[24] ;
- le processeur de requête exécute les opérations demandées. Selon le modèles de SGBD, ces opérations peuvent être formulées dans un langage de commande, ou à l'aide d'une interface graphique du type QBE (query by example en français requête par l'exemple)[24] ;
- la majorité des SGBD comportent au moins un langage de commande. Ce langage de requête permet de manipuler le contenu de la base de données. Reconnu par la majorité des SGBD du marché, SQL est devenu le langage standard de facto[23].
Les outils du SGBD servent à créer des compte-rendus (reports), des écrans pour la saisie des informations, importer et exporter les données de et vers la base de données, et manipuler le catalogue[23]. Ces outils sont utilisés par l'administrateur de bases de données pour effectuer des sauvegardes, des restauration de données, autoriser ou interdire l'accès à certaines informations, et effectuer des modifications du contenu de la base de données - création, lecture, modification et suppression d'informations, abrégé CRUD (anglais create, read, update, delete). Ces outils servent également à surveiller l'activité du moteur et effectuer des opérations de tuning[25].
Les SGBD contemporains de haut de gamme comportent de nombreuses extensions qui offrent des fonctionalités auxiliaires, leur construction reste cependant similaire à la plupart des SGBD[26].
Dans un SGBD relationnel, les demandes formulées au SGBD sont typiquement traitées en 5 étapes :
- les logiciel client communiquent avec le SGBD en utilisant son interface de programmation via un réseau. Un dispositif de communication du SGBD vérifie l'identité du client, puis transmet les requêtes du client vers le noyau du SGBD et transmet au client les informations extraites par le SGBD[26] ;
- le SGBD crée ensuite un thread en vue de traiter la requête. Un programme contrôle l'ensemble des threads est décide lesquels sont exécutés immédiatement et lesquels seront exécutés plus tard, en fonction de la charge de travail de l'ordinateur[26] ;
- lors de l'exécution du thread, un compilateur transforme le texte exprimé dans le langage de requête du SGBD en un plan d'exécution dont la forme imite celle d'une expression algébrique utilisant l'algèbre relationnelle, puis un ensemble de programmes "opérateurs" calculent le résultat de l'expression en effectuant des opérations telles que la jointure, le produit cartésien, le tri et la sélection[26] ;
- les opérateurs font appel au moteur de base de données, celui-ci exécute des algorithmes (appelés access method en anglais) en vue de retrouver les informations et entretenir les structures des fichiers de la base de données[26] ;
- une fois les informations obtenues par le programme de manipulation de fichiers, celles-ci sont envoyées au thread d'exécution puis ensuite au dispositif de communication qui les transmet au client[26].
Moteur de base de données
Article détaillé : moteur de base de données.Partie centrale du SGBD, le moteur de base de données effectue les opérations d'enregister et de retrouver les données. Selon le SGBD, La base de données peut être composées d'un ou de plusieurs fichiers; Le rôle du moteur est de manipuler ces fichiers[24].
Les indexes sont des structures destinées à accélérer les opérations de recherche, elles sont entretenues par le moteur de base de données. Les vues sont des tables imaginaires crées à partir d'autres tables, et leur contenu est entretenu par le moteur de base de données. Celui-ci manipule également le catalogue, contrôle les transactions, vérifie la cohérence des informations et vérifie que les utilisateurs accèdent uniquement à des informations autorisées[24] :
- contrôle des transactions : lors d'une transaction plusieurs modifications sur la base de données correspondent à une seule opération; Le moteur assure la cohérence du contenu de la base de données, y compris en cas d'échec ou de panne. Le moteur vérifie que les modifications concurrentes des mêmes informations n'aboutissent pas à un résultat incohérent[2] ;
- sécurité : le moteur vérifie qu'aucun utilisateur n'accède à des informations non autorisées, et qu'aucun utilisateur n'effectue des modifications qui seraient contraires aux règles de cohérence[2]. ;
- accès aux fichiers : le moteur manipule l'espace réservé au stockage. Les informations sont groupées par nature, et chaque fichier stocke une collection d'informations de même nature. Le programme d'accès au fichier structure les différents fichiers conformément au schéma d'organisation de la base de données[2].
Le moteur utilise des mémoire tampon : C'est un emplacement de mémoire centrale utilisé pour stocker temporairement des informations en transit. Les informations sont récupérées en bloc depuis les fichiers, puis placés dans des mémoires tampon. Lors des lectures suivantes l'information est récupérée depuis la mémoire tampon existante - opération beaucoup plus rapide que la lecture d'un fichier. Les opérations de lecture des fichiers sont ainsi diminuées, et les opérations d'écriture sont décalées, ce qui accélère le SGBD[2].
Les opérations effectuées par le moteur sont souvent inscrites dans un fichier journal, ce qui permet de les annuler en cas d'incident - panne ou annulation d'une transaction[26].
Indépendance des données
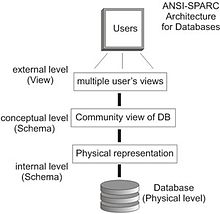 modèle à 3 vues ANSI/SPARC
modèle à 3 vues ANSI/SPARCDans un dispositif de base de données - qui comporte un logiciel applicatif, un SGBD et une base de données - la manière dont les informations sont présentées aux utilisateurs diffère de la manière dont sont organisées les informations, et celle-ci diffère de la manière dont les informations sont enregistrées dans des fichiers. Cette construction à 3 points de vue est basée sur le modèle de référence ANSI/SPARC[1],[5].
Chacune des 3 vues peuvent être modifiées par exemple en formulant des requêtes dans le langage du SGBD. L'indépendance des données est la capacité d'un SGBD de permettre la modification de n'importe laquelle des trois vues sans que cela nécessite de modification des autres vues[1],[5] :
- vue utilisateur : Les utilisateurs ne voient qu'une partie des informations contenues dans la base de données, ce que voit l'utilisateur sont des informations dérivées du contenu de la base de données et présentées d'une manière différente. Il existe différentes vues adaptées à chacun des rôles joués par les utilisateurs[1],[5] ;
- schéma conceptuel : c'est le modèle de l'organisation logique des informations enregistrées dans la base de données, c'est une vue de la totalité des informations enregistrées. Le schéma est souvent organisé de la même manière que les objets du monde réel auquel les informations se rapportent et décrit en utilisant la notation entité-association[1],[5] ;
- schéma physique : Ce sont les caractéristiques des structures en place pour permettre le stockage permanent des informations sous forme d'enregistrements dans des fichiers. Ceci comprends l'espace réservé à chaque information, la manière dont les informations sont représentées sous forme de suite de bits, et la présence d'indexes destinés à accélérer les opérations de recherche[1],[5].
Il y a indépendance des données si le schéma conceptuel peut être modifié sans nécessiter de modification du point de vue de l'utilisateur ni de la structure physique, et si la structure physique peut être modifiée sans que cela nécessite de modifications du schéma conceptuel ou du point de vue de l'utilisateur[1],[5].
Les usagers
Il existe plusieurs catégories d'usagers des SGBD, parmi lesquelles il y a l'administrateur de bases de données, le concepteur de base de données, le développeur, ainsi que les utilisateurs - plus ou moins avisés - des systèmes informatiques.
L'administrateur de bases de données (anglais database administrator abr. DBA) est un expert en SGBD, il s'occupe d'installer et de maintenir le SGBD ainsi que les outils annexes qui l'accompagne. Il est la personne responsable de l'intégrité, de la sécurité, la disponibilité des informations contenues dans les bases de données ainsi que de la performance du SGBD. Il protège les informations contre les accidents dus à des mauvaises manipulation, des erreurs de programmation, des utilisations malveillantes, ou des pannes qui entraineraient des détérioration du contenu des bases de données. Pour ce faire, l'administrateur de base de données autorise ou interdit l'accès aux informations et surveille l'activité du SGBD. Il effectue régulièrement des copies de sauvegarde en vue de permettre la récupération de données qui ont été perdues ou déteriorées et effectue des réglages de tuning en vue d'améliorer la performance du SGBD. L'administrateur utilise les outils d'administration de base de données ou le langage de commande du SGBD[2],[27].
Le concepteur de base de données (anglais database designer) est la personne qui identifie les informations qui seront enregistrées dans la base de données, les relations entre ces informations et les contraintes telles que la présence ou pas de redondance. Le concepteur de base de données a une connaissance approfondie de l'usage qui est fait de ces informations, et les règles qui en découlent. Il est reponsable d'organiser la base de données de manière appropriée en mettant en place les structures nécessaires au stockage des informations[2].
Les développeurs créent des logiciels applicatifs et des batch dans un ou l'autre langage de programmation de haut niveau. Chaque logiciel cible une activité en particulier - par exemple retrouver des livres dans une bibliothèque - et est destiné aux autres usagers du SGBD. Le développeur travaille avec une personne exerçant l'activité en question, en vue de déterminer les besoins caractéristiques de cette activité puis il détermine l'architecture du produit, et le met en œuvre en rédigeant le code source. Le logiciel comporte des instructions qui font appel au SGBD pour rechercher ou modifier les informations. Certains utilisateurs expérimentés, qui connaissent un ou l'autre langage de programmation, créent des programmes pour leur propre usage[2],[27],[28].
les utilisateurs avisés ont les connaissances nécessaires pour utiliser le langage de commande du SGBD et accédent aux données à partir de leur ordinateur personnel. Ils ont été autorisés par l'administrateur de voir certaines informations et de les modifier. Les utilisateur avisés peuvent rechercher, ajouter, modifier, ou supprimer des données en utilisant le langage de commande du SGBD, alors que les utilisateurs profanes n'utilisent jamais le langage de commande mais accèdent aux informations à travers des logiciels applicatifs prévus à cet effet[28].
Les utilisateurs profanes accèdent aux informations à travers un logiciel applicatif. Ils exécutent des commandes ou choisissent des menus et n'ont pas connaissance du langage de commande ni de l'organisation de la base de données. Les opérations effectuées par ces utilisateurs sont moins sophistiquées et limitées aux possibilités offertes par le logiciel applicatif[28].
Le marché
Les SGBD sont des logiciels complexes et stratégiques, utilisés dans de très nombreuses applications informatiques, parmi lesquelles le e-commerce, les dossiers médicaux, les paiements, les ressources humaines, la gestion de la relation client et la logistique ainsi que les blogs et les wikis, ils sont le résultat de dizaines d'années de recherche scientifique et industrielle. Les premiers SGBD de l'histoire ont fortement influencé ce secteur de marché, et les idées de ces pionniers sont encore largement copiées et réutilisées par les SGBD contemporains. Le marché des SGBD est très ténu, dominé par une poignée de produits concurrents de haut de gamme[26].
Le volume des ventes de SGBD relationnels est estimé entre 6 et 10 milliards de dollars par année en 2005[11]. En 2008 les trois tenors du marché que sont IBM DB2, Oracle Database et Microsoft SQL Server occupent 80 % du marché des SGBD relationnels[3].
En 2002 le marché des SGBD est réparti en 3 segments[29] :
- le premier segment est occupé par les trois grandes marques, largement implantées et reconnues que sont IBM DB2, Oracle Database et Microsoft SQL Server. Ces produits sont très populaires, et peuvent être utilisés pour de nombreuses applications. DB2 et Oracle fonctionnent sur de nombreux types d'ordinateurs qui vont des mainframe jusqu'aux ordinateurs de poche[29] ;
- dans le deuxième segment se trouvent des produits un peu moins populaires tels que Sybase et Informix, ils sont un peu moins implantés, moins connus, et leurs éditeurs sont des sociétés un peu plus petites et avec moins de personnel[29] ;
- dans le troisième segment se trouvent tous les autres SGBD, dont certains sont notables dans les utilisations spécialisées ou des marchés de niche. Par exemple Teradata de NCR est un SGBD utilisé pour les bases de données géantes et les datawarehouse. Dans ce segment de marché se trouvent les SGBD open source tels que PostgreSQL et MySQL ainsi que les SGBD orientés objet tels que Versant ou ObjectDesign[29].
Marché de niche en 2002, le marché des SGBD Open Source est estimé à 850 millions de dollars en 2008, et selon prévisions à 1.2 milliards de dollars en 2010, ce coût comprends les licences, les contrats de garantie et d'assistance technique. Alors que les SGBD de grande marque sont appréciés pour les applications stratégiques en raison de leur robustesse, leur richesse et leur durabilité, les SGBD open source sont plus simples, n'offrant pas toutes les fioritures des produits de grande marque, ils sont appréciés pour leur facilité d'utilisation et recherchés par les petites et moyennes institutions. Divers clients espèrent pouvoir remplacer des coûteux SGBD de grande marque par des SGBD open source moins coûteux, mais de tels remplacement sont rares, et les SGBD MySQL et PostgreSQL sont utilisés pour de nouvelles applications, ceci en raison des difficultés de migration[30],[31]
Pour l'acheteur
Le choix du SGBD est souvent une décision stratégique pour une institution. Le coût d'acquisition d'un SGBD qui supporte plusieurs milliers d'utilisateurs et une base de données de grande dimensions peut approcher les 1 million de dollars. En 1993 il existe différents SGBD relationnels, et ceux-ci sont considérés comme suffisamment matures pour être utilisés dans des applications stratégiques. Les produits sont complexes, les différences sont parfois subtiles, ce qui rends le choix difficile pour l'acheteur[32]. Dix ans plus tard le choix n'est plus aussi difficile qu'il ne l'était avant, le nombre d'éditeurs de SGBD a diminué du fait de fusions et le marché est dominé par un petit nombre d'acteurs majeurs[29].
D'après un sondage réalisé en 1993 par le magazine Network World, il en ressort que les critères de choix du SGBD les plus importants au yeux des acheteurs sont la fiabilité, la performance, la conformité aux normes, la palette d'ordinateurs supportés, et la facilité d'utilisation. Le prix n'apparaît qu'en dixième position. Toujours d'après ce sondage, 70% des acheteurs se disent prêts à débourser entre 2 000 et 25 000 dollars pour l'acquisition d'un SGBD[32].
Les questions fréquentes des acheteurs concernent la performance, les caractéristiques du langage de commande, du contrôle de la concurrence ainsi que les type de données disponibles. La question de la performance apparait souvent en haut de la liste des acheteurs et en bas de la liste des vendeurs; raison pour laquelle les essais et les benchmarks sont une pratique courante. Les caractéristiques du langage de commande SQL renseignent sur la syntaxe à laquelle devront se conformer les requêtes envoyées au SGBD. Le standard SQL a été modifié à plusieurs reprises, il existe 3 niveaux de conformité, et le langage SQL reconnu par chaque SGBD du marché se rapproche d'un ou l'autre de ces différents standards[32].
Une entreprise de taille moyenne utilise couramment plusieurs SGBD simultanément, le choix du SGBD étant rarement anticipé, souvent imposé par l'arrivée d'un logiciel applicatif, et difficilement réversible: Il arrive que la société acquiert un logiciel applicatif qui ne fonctionne sur aucun des SGBD qu'elle possède déjà. Il arrive également qu'une société motive l'achat d'un nouveau SGBD par la volonté d'utiliser les technologies les plus récentes et les plus éminentes. Le replacement d'un ancien SGBD par un nouveau est difficile en raison du manque de compatibilité entre les différents produits - ce qui rends nécessaire d'adapter les logiciels applicatifs au nouveau venu. Le résultat est que souvent les logiciels applicatifs ne sont pas adaptés, et le vieux SGBD continue d'être utilisé en même temps que les nouveaux produits[29].
Quelques SGBD
Système de gestion de base de données Nom SGBD Année Editeur Caractéristiques type de logiciel SQL Multivalué Licence Apache Derby 1996 Apache Software Foundation embarqué[16], relationnel, centralisé[33] Composant logiciel Licence Apache DB2 1983 IBM pour entreprises, groupes de travail, particuliers[34] serveur 
Licence propriétaire dBase 1978 Ashton-Tate relationnel, pour particuliers[35] L4G Licence propriétaire FileMaker Pro 1985 FileMaker relationnel, pour groupes de travail[36] logiciel applicatif Licence propriétaire Firebird 1981 Firebird Foundation relationnel, centralisé, embarqué, pour groupes de travail et entreprises[16],[37] serveur Interbase Public Licence HSQLDB 2000 Thomas Mueller relationnel, embarqué, centralisé, pour groupes de travail et particuliers[16],[38] Composant logiciel Licence BSD HyperFile 1993 PC Soft composant logiciel[39] Licence propriétaire Informix 1981 IBM pour entreprises, groupes de travail, distribué[34] serveur Licence propriétaire Ingres 1974 Ingres Corporation relationnel, spatial, centralisé, distribué[40] serveur GPL Caché 1997 InterSystems objet, pour entreprises, distribué[41] serveur Licence propriétaire MariaDB 2009 Monty Program Ab serveur GPL MaxDB[42],[43] 1977 SAP AG et MySQL AB objet-relationnel, pour entreprises et groupes de travail, centralisé[44] composant logiciel GPL Microsoft Access 1992 Microsoft relationnel, pour particuliers et groupes de travail[36],[45] L4G Licence propriétaire Microsoft SQL Server 1989 Microsoft[46] entreprises, groupes de travail, particuliers, relationnel, distribué[47] serveur Licence propriétaire MySQL 1995 Oracle Corporation[48] et MySQL AB centralisé, embarqué[16], distribué, pour entreprises[49], groupes de travail et particuliers[50] serveur GPL OpenOffice.org Base 2002 Oracle Corporation[48] Logiciel applicatif LGPL Oracle Database 1979 Oracle Corporation entreprises, groupes de travail, particuliers, relationnel, spatial, distribué[51] serveur Licence propriétaire Paradox 1987[52] Corel[53] logiciel applicatif Licence propriétaire Pick 1968 Pick System serveur Licence propriétaire PostgreSQL 1985 Michael Stonebraker serveur Licence BSD Progress 1981 Progress Software Corporation L4G Licence propriétaire SQLite 2000 D. Richard Hipp embarqué[16] composant logiciel Domaine public Notes et références
- (en)Database Management System Concepts,FK Publications,(ISBN 9789380006338)
- (en)S. Sumathi, S. Esakkirajan,Fundamentals of Relational Database Management Systems,Springer - 2007,(ISBN 9783540483977)
- Global RDBMS market
- (en)Carlos Coronel, Steven Morris, Peter Rob,Database systems: design, implementation, and management,Cengage Learning - 2009,(ISBN 9780538469685)
- (en)Isrd Group,Introduction to Database Management Systems,Tata McGraw-Hill Education, 2005,(ISBN 9780070591196)
- (en)Setrag Khoshafian,A Guide to developing client/server SQL applications,M. Kaufmann Publishers - 1992,(ISBN 9781558601475)
- (en)Mark Johansen,A Sane Approach to Database Design,Lulu.com - 2008,(ISBN 9781435733381)
- (en)Rajesh Narang,Database Management Systems,PHI Learning Pvt. Ltd. - 2006,(ISBN 9788120326453)
- P.C. Dressen, The Data/BASIC Language - A Data Processing Language for Non-Professional Programmers, Proc SJCC 36, AFIPS, Spring 1970
- (en)Allen G. Taylor,Database Development For Dummies,John Wiley & Sons - 2011,(ISBN 9781118085257)
- (en)Thomas M. Connolly - Carolyn E. Begg,Database systems: a practical approach to design, implementation, and management,Pearson Education - 2005,(ISBN 9780321210258)
- (en)Philip J. Pratt - Joseph J. Adamski,Concepts of Database Management,Cengage Learning - 2007,(ISBN 9781423901471)
- (en)Aditya Kumar Gupta,Taxonomy of Database Management System,Firewall Media - 2007,(ISBN 9788131800065)
- (en)S. K. Singh,Database Systems: Concepts, Design and Applications,Pearson Education India - 2009,(ISBN 9788177585674)
- (en)Saeed K. Rahimi - Frank S. Haug,Distributed Database Management Systems: A Practical Approach,John Wiley and Sons - 2010,(ISBN 9780470407455)
- (en)AUUGN,oct. 2005
- (en)Hossein Bidgoli, The Internet encyclopedia, Volume 2, Hossein Bidgoli, (ISBN 9780471222040)
- (en)Nick Rozanski, Eoin Woods, Solfware systems architecture: Working with Stakeholders using viewpoints and perspectives, Addison-Wesley, (ISBN 9780132906128)
- http://www.microdata-alumni.org/historical.htm#history_of_pick
- http://www.jbase.com/new/about/jbase_temenos_mpower1.html http://www.temenos.com/Sectors/
- (en)THE HISTORY AND HERITAGE OF SCIENTIFIC AND TECHNOLOGICAL iNFORMATION SYSTEMS,Information Today Inc.
- (en)Patrick O'Neil - Elizabeth O'Neil,Database--principles, programming, and performance,Morgan Kaufmann - 2001,(ISBN 9781558604384)
- (en)Lex de Haan - Daniel Fink - Tim Gorman - Inger Jorgensen - Karen Morton,Beginning Oracle SQL,Apress - 2009,(ISBN 9781430271970)
- (en)Colin Ritchie,Database Principles and Design,Cengage Learning EMEA - 2008,(ISBN 9781844805402)
- (en)Hossein Bidgoli,MIS 2010,Cengage Learning - 2010,(ISBN 9780324830088)
- (en)Joseph M. Hellerstein, Michael Stonebraker, James Hamilton,Architecture of a Database System,Now Publishers Inc - 2007,(ISBN 9781601980786)
- (en)Latif Al-Hakim,Challenges of managing information quality in service organizations,Idea Group Inc (IGI) - 2007,(ISBN 9781599044217)
- (en)Catherine Ricardo,Databases Illuminated,Jones & Bartlett Publishers - 2011,(ISBN 9781449606008)
- (en)Craig Mullins,Database administration: the complete guide to practices and procedures, Addison-Wesley Professional - 2002,(ISBN 9780201741292)
- [1]
- [2]
- (en)Network World,3 mai 1993,Vol. 10 - N° 18,(ISSN 0887-7661)
- Apache Derby Tutorial
- (en)Douglas W. Spencer,IBM software for e-business on demand,Maximum Press - 2004,(ISBN 9781931644174)
- InfoWorld,10 avr. 1989,Vol. 11 - N° 15,(ISSN 0199-6649)
- (en)Jesse Feiler,FileMaker Pro 10 In Depth,Que Publishing - 2009,(ISBN 9780768688139)
- Firebird: about Firebird
- HyperSQL Features
- composant du L4G WinDev
- Ingres community wiki
- InterSystems Caché
- anciennement nommé ADABAS
- (en)MySQL AB,MySQL administrator's guide and language reference,Sams Publishing - 2006,(ISBN 9780672328701)
- SAP community network - About SAP MaxDB
- Michael R. Groh,Access 2010 Bible,John Wiley and Sons - 2010,(ISBN 9780470475348)
- acheté à Sybase en 1994
- Jérôme Gabillaud,SQL Server 2008 - Administration d'une base de données avec SQL Server Management Studio,Editions ENI - 2009,(ISBN 9782746047044)
- vendu à Sun Microsystems en 2009
- MySQL Enterprise Edition]
- (en)MySQL AB,MySQL administrator's guide and language reference,Sams Publishing - 2006,(ISBN 9780672328701)
- (en)Rick Greenwald, Robert Stackowiak, Jonathan Stern, O'Reilly & Associates,Oracle essentials: Oracle database 10g,O'Reilly Media, Inc. - 2004,(ISBN 9780596005856)
- (en)Borland history
- racheté à Borland
Annexes
Bibliographie
- Introduction aux systèmes de gestion de base de données ([lire en ligne (page consultée le juin 2009)]
- Introduction aux systèmes de gestion de base de données et aux bases de données ([lire en ligne (page consultée le juin 2009)])
Articles connexes


Wikimedia Foundation. 2010.