- Algorithme de Gauss-Newton
-
En mathématiques, l'algorithme de Gauss-Newton est une méthode de résolution des problèmes de moindres carrés non linéaires. Elle peut être vue comme une modification de la méthode de Newton dans le cas multidimensionnel afin de trouver le minimum d'une fonction (à plusieurs variables). Mais l'algorithme de Gauss-Newton est totalement spécifique à la minimisation d'une somme de fonctions au carré et présente le grand avantage de ne pas nécessiter les dérivées secondes, parfois complexes à calculer.
Les problèmes de moindres carrés non linéaires surviennent par exemple dans les problèmes de régressions non linéaires, où des paramètres du modèle sont recherchés afin de correspondre au mieux aux observations disponibles.
Cette méthode est due à Carl Friedrich Gauss.
Sommaire
Algorithme
Soit m fonctions ri (
 ) de n variables
) de n variables  avec m≥n, l'algorithme de Gauss–Newton doit trouver le minimum de la somme des carrés[1] :
avec m≥n, l'algorithme de Gauss–Newton doit trouver le minimum de la somme des carrés[1] :En supposant une valeur initiale
 du minimum, la méthode procède par itérations:
du minimum, la méthode procède par itérations:où l'incrément
 vérifie les équations normales
vérifie les équations normalesIci, on note par r le vecteur des fonctions ri, et par Jr la matrice jacobienne m×n de r par rapport à β, tous les deux évalués en βs. La matrice transposée est notée à l'aide de l'exposant T.
Dans les problèmes d'ajustement des données, où le but est de trouver les paramètres
 d'un certain modèle
d'un certain modèle  permettant le meilleur ajustement aux observations (xi,yi),, les fonctions ri sont les résidus
permettant le meilleur ajustement aux observations (xi,yi),, les fonctions ri sont les résidusAlors, l'incrément
peut s'exprimer en fonction de la jacobienne de la fonction f:Dans tous les cas, une fois connue l'estimation à l'étape s, les équations normales permettent de trouver l'estimation à l'étape suivante; pour résumer, on a :
L'ensemble du terme de droite est calculable car ne dépend que de
 et permet de trouver l'estimation suivante.
et permet de trouver l'estimation suivante.Remarques
L'hypothèse m≥n est nécessaire, car dans le cas contraire la matrice
 serait non inversible et les équations normales ne pourraient être résolues.
serait non inversible et les équations normales ne pourraient être résolues.L'algorithme de Gauss–Newton peut être dérivé par approximation linéaire du vecteur de fonctions ri. En utilisant le Théorème de Taylor, on peut écrire qu'à chaque itération
avec
 ; notons que
; notons que  représente la vraie valeur des paramètres pour laquelle les résidus
représente la vraie valeur des paramètres pour laquelle les résidus  s'annulent. Trouver l'incrément revient à résoudre
s'annulent. Trouver l'incrément revient à résoudrece qui peut se faire par la technique classique de régression linéaire et qui fournit exactement les équations normales.
Les équations normales sont un système de m équations linéaires d'inconnu
. Ce système peut se résoudre en une étape, en utilisant la factorisation de Cholesky ou, encore mieux, la décomposition QR de Jr. Pour de grands systèmes, une méthode itérative telle que la méthode du gradient conjugué peut être plus efficace. S'il existe une dépendance linéaire entre les colonnes Jr, la méthode échouera car deviendra singulier.Exemple
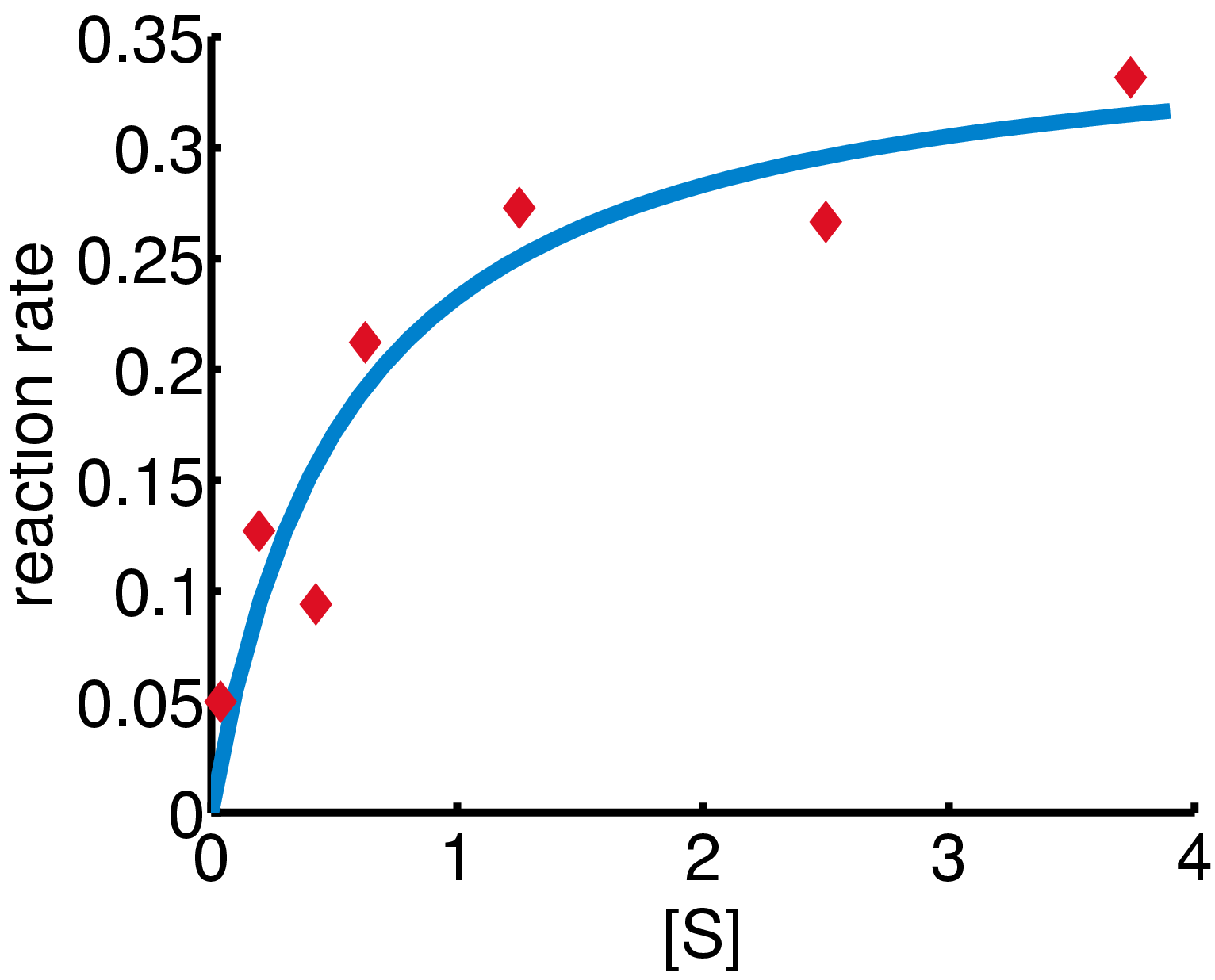
 Courbe calculée avec
Courbe calculée avec
 et
et  (en bleu) contre les données observées (en rouge).
(en bleu) contre les données observées (en rouge).Dans cet exemple, l'algorithme de Gauss–Newton est utilisé pour ajuster un modèle en minimisant la somme des carrés entre les observations et les prévisions du modèle.
Dans une expérience de biologie, on étudie la relation entre la concentration du substrat [S] et la vitesse de réaction dans une réaction enzymatique à partir de données reportées dans le tableau suivant.
-
i 1 2 3 4 5 6 7 [S] 0.038 0.194 0.425 0.626 1.253 2.500 3.740 rate 0.050 0.127 0.094 0.2122 0.2729 0.2665 0.3317
On souhaite ajuster les données à la courbe de la forme:
L'estimation par moindres carrés porte sur les paramètres Vmax et KM.
On note xi et yi les valeurs de [S] et la vitesse de réaction, pour
 On pose β1 = Vmax et β2 = KM. Nous allons chercher β1 et β2 pour minimiser la somme des carrés des résidus
On pose β1 = Vmax et β2 = KM. Nous allons chercher β1 et β2 pour minimiser la somme des carrés des résidus (
( )
)
La jacobienne
 du vecteur des résidus ri par rapport aux inconnus βj est une matrice
du vecteur des résidus ri par rapport aux inconnus βj est une matrice  dont la ligne n° i est
dont la ligne n° i estCommençant avec l'estimation initiale β1=0,9 et β2=0,2, il suffit de 5 itérations de l'algorithme de Gauss–Newton pour atteindre les estimations optimales
 et
et  . Le critère de la somme des carrés des résidus chute de 1,202 à 0,0886 en 5 itérations. Le tableau suivant détaille les cinq itérations:
. Le critère de la somme des carrés des résidus chute de 1,202 à 0,0886 en 5 itérations. Le tableau suivant détaille les cinq itérations:-
Itération Estimation Somme des carrés des résidus 1 [0,9;0,2] 1,4455000 2 [0,33266;0,26017] 0,0150721 3 [0,34281;0,42608] 0,0084583 4 [0,35778;0,52951] 0,0078643 5 [0,36141;0,55366] 0,0078442 6 [ 0,3618;0,55607] 0,0078440
La figure ci-contre permet de juger de l'adéquation du modèle aux données en comparant la courbe ajustée (bleue) aux observations (rouge).
Propriété de convergence
On peut démontrer que l'incrément δβ est une direction de descente pour S [2], et que si l'algorithme converge, alors la limite est un point stationnaire pour la somme des carrés S. Toutefois, la convergence n'est pas garantie, pas plus qu'une convergence locale contrairement à la méthode de Newton.
La vitesse de convergence de l'algorithme de Gauss–Newton peut approcher la vitesse quadratique[3]. L'algorithme peut converger lentement voire ne pas converger du tout si le point de départ de l'algorithme est trop loin du minimum ou si la matrice
est mal conditionnée.L'algorithme peut donc échouer à converger. Par exemple, le problème avec m = 2 équations et n = 1 variable, donné par
L'optimum se situe en β = 0. Si λ = 0 alors le problème est en fait linéaire et la méthode trouve la solution en une seule itération. Si |λ| < 1, alors la méthode converge linéairement et les erreurs décroissent avec un facteur |λ| à chaque itération. Cependant, si |λ| > 1, alors la méthode ne converge même pas localement[4].
Dérivation à partir de la méthode de Newton
Dans ce qui suit, l'algorithme de Gauss–Newton sera tiré de l'algorithme d'optimisation de Newton; par conséquent, la vitesse de convergence sera au plus quadratique.
La relation de récurrence de la méthode de Newton pour minimiser une fonction S de paramètres
, estoù g représente le gradient de S et H sa matrice hessienne. Puisque
 , le gradient est
, le gradient estLes éléments de la Hessienne sont calculés en dérivant les éléments du gradient, gj, par rapport à βk
La méthode de Gauss–Newton est obtenue en ignorant les dérivées d'ordre supérieur à deux. La Hessienne est approchée par
où
 est l'élément (i,j) de la jacobienne . Le gradient et la hessienne approchée sont alors
est l'élément (i,j) de la jacobienne . Le gradient et la hessienne approchée sont alorsCes expressions sont replacées dans la relation de récurrence initiale afin d'obtenir la relation récursive
La convergence de la méthode n'est pas toujours garantie. L'approximation
doit être vraie pour pouvoir ignorer les dérivées du second ordre. Cette approximation peut être valide dans deux cas, pour lesquels on peut s'attendre à obtenir la convergence[5] :
- les valeurs de la fonction ri sont petites en magnitude, au moins près du minimum ;
- les fonctions sont seulement faiblement non linéaires, si bien que
 est relativement petit en magnitude.
est relativement petit en magnitude.
Versions améliorées
Avec la méthode de Gauss–Newton, la somme des carrés S peut ne pas décroître à chaque itération. Toutefois, puisque
est une direction de descente, à moins que  soit un point stationnaire, il se trouve que
soit un point stationnaire, il se trouve que  pour tout α > 0 suffisamment petit. Ainsi, en cas de divergence, une solution est d'employer une fraction, α, de l'incrément, dans la formule de mise à jour
pour tout α > 0 suffisamment petit. Ainsi, en cas de divergence, une solution est d'employer une fraction, α, de l'incrément, dans la formule de mise à jour .
.
En d'autres termes, le vecteur d'incrément est trop long, mais pointe bien vers le bas, si bien que parcourir une fraction du chemin fait décroître la fonction objectif S. Une valeur optimale pour α peut être trouvée en utilisant un algorithme de recherche linéaire : la magnitude de α est déterminée en trouvant le minimum de S en faisant varier α sur une grille de l'intervalle 0 < α < 1.
Dans le cas où la direction de l'incrément est telle que α est proche de zéro, une méthode alternative pour éviter la divergence est l'algorithme de Levenberg-Marquardt. Les équations normales sont modifiées de telle sorte que l'incrément est décalé en direction de la descente la plus forte
 ,
,
où D est une matrice diagonale positive. Remarquons que lorsque D est la matrice identité et que
 , alors
, alors  , par conséquent la direction de s'approche de la direction du gradient
, par conséquent la direction de s'approche de la direction du gradient  .
.Le paramètre de Marquardt, λ, peut aussi être optimisé par une méthode de recherche linéaire, mais ceci rend la méthode fort inefficace dans la mesure où le vecteur d'incrément doit être re-calculé à chaque fois que λ change.
Algorithmes associés
Dans une méthode quasi-Newton, comme celle due à Davidon, Fletcher et Powell, une estimation de la matrice Hessienne,
 , est approchée numériquement en utilisant les premières dérivées
, est approchée numériquement en utilisant les premières dérivées  .
.Une autre méthode pour résoudre les problèmes de moindres carrés en utilisant seulement les dérivées premières est l'algorithme du gradient. Toutefois, cette méthode ne prend pas en compte les dérivées secondes, même sommairement. Par conséquent, cette méthode s'avère particulièrement inefficace pour beaucoup de fonctions.
Notes et références
(en) Cet article est partiellement ou en totalité issu de l’article en anglais intitulé « Gauss–Newton algorithm » (voir la liste des auteurs)
- (en) Åke Björck, Numerical methods for least squares problems, Philadelphie, SIAM, 1996 (ISBN 978-0-89871-360-2) (LCCN 96003908)
- Björck, p. 260
- Björck, p. 341-342
- Roger Fletcher (en), Practical methods of optimization, New York, [[John Wiley & Sons|John Wiley & Sons]], 1987 (ISBN 978-0-471-91547-8), p. 113
- (en) Jorge Nocedal et Stephen J. Wright, Numerical optimization, New York, Springer, 1999, 2e éd. (ISBN 978-0-387-98793-4)








![\text{rate}=\frac{V_{\max}[S]}{K_M+[S]}](3/01300327254fee29bc72dd4707d4fe1d.png)









Wikimedia Foundation. 2010.