- Discret cosine transform
-
Transformée en cosinus discrète
La transformée en cosinus discrète ou TCD (de l'anglais : DCT ou Discrete Cosine Transform) est une transformation proche de la transformée de Fourier discrète (DFT). Le noyau de projection est un cosinus et génère donc des coefficients réels, contrairement à la DFT, dont le noyau est une exponentielle complexe et qui génère donc des coefficients complexes. On peut cependant exprimer la DCT en fonction de la DFT, qui est alors appliquée sur le signal symétrisé.
La variante la plus courante de la transformée en cosinus discret est la DCT type-II, souvent simplement appelée « la DCT ». Son inverse, qui correspond au type-III est souvent simplement appelée « IDCT ».
 Une DCT 2D comparée à une DFT. Les zones claires représentent les coefficients non-nuls
Une DCT 2D comparée à une DFT. Les zones claires représentent les coefficients non-nuls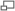
Sommaire
Applications
- La DCT, et en particulier la DCT-II est très utilisée en traitement du signal et de l'image, et spécialement en compression. La DCT possède en effet une excellente propriété de "regroupement" de l'énergie : l'information est essentiellement portée par les coefficients basses fréquences. Pour les images naturelles, la DCT est la transformation qui se rapproche le plus de la transformée de Karhunen-Loève qui fournit une décorrélation optimale des coefficients pour un signal markovien. En pratique, les procédés de compression font donc l'hypothèse qu'une image naturelle peut être modélisée comme la réalisation d'un processus markovien et approximent la transformée de Karhunen-Loève, trop complexe en calcul et dépendante des données, par une DCT. L'intérêt d'une transformation se voit particulièrement bien sur une figure (voir ci-contre). Seuls un petit nombre de coefficients sont non-nuls, et peuvent être utilisés pour reconstruire l'image par transformée inverse (IDCT) lors de la décompression. Le gain en termes de compression vient de la suppression des coefficients nuls ou proches de zéro. Ce genre de mécanisme est utilisé dans les standards JPEG et MPEG, qui utilisent une DCT 2D sur des blocs de pixels de taille 8x8 (pour des raisons de complexité).
- Les formats de compression de son avec perte AAC, Vorbis et MP3 utilisent une version modifiée de cette technique, la transformée en cosinus discrète modifiée, TCDM (MDCT en anglais).
- La DCT est aussi employée pour la résolution de systèmes d'équations différentielles par des méthodes spectrales.
Définition
La DCT est une fonction linéaire inversible RN → RN ou de manière équivalente une matrice carrée N × N inversible. Il existe plusieurs légères variantes de la DCT. Voici les quatre types les plus connus.
Le développement des algorithmes de calcul rapide des transformées DCT se basent sur la possibilité de décomposer la matrice de définition sous forme d'un produit de matrices dont le calcul est plus simple, et permet de réduire le nombre de multiplications scalaires, en profitant des identités remarquables de périodicité et symétries des fonctions sinusoïdales. Ainsi, on peut décomposer toute transformée DCT de RN en transformées plus simples en décomposant N en produit de facteurs premiers, et en composant des sous-transformées dans Rn où n est l'un de ces facteurs. En particulier, de nombreuses optimisations ont été développées quand N est une puissance de 2.
Cela revient à réécrire la matrice N × N sous forme de produit de sous-matrices identiques (disposées en pavage régulier et utilisant donc des coefficients réels communs ou différenciés uniquement par leur signe) et de matrices à coefficients unitaires ou nuls (-1, 0 ou 1), ces dernières ne nécessitant pas de multiplication.
DCT-I
On peut rendre cette transformée orthogonale (à une constante multiplicative près) en multipliant x0 et xN-1 par √2 et réciproquement X0 et XN-1 par 1/√2. Cette normalisation casse toutefois la correspondance avec une DFT.
On peut noter que la DCT-I n'est pas définie pour
 , contrairement aux autres types qui sont définis pour tout N positif.
, contrairement aux autres types qui sont définis pour tout N positif.DCT-II
Cette variante DCT est la plus courante et la plus utilisée. Elle est généralement simplement appelée « la DCT ». De la même manière que pour la DCT-I, on peut rendre cette transformation orthogonale en multipliant X0 par 1/√2. Cette forme normalisée est très utilisée en pratique mais casse la correspondance avec la DFT.
Exemple pour N = 8
Un développement optimisé de cette transformée pour le cas N=8 (utilisé dans JPEG et MPEG) est obtenu en réécrivant la transformée sous forme matricielle et en factorisant la décomposition, pour réduire le nombre de multiplications scalaires nécessaires. Par exemple, la décomposition suivante est utilisée pour la factorisation par l'algorithme de Chen[1] , ici orthogonalisée (voir remarque ci-dessus) :
- Coefficients constants de calcul
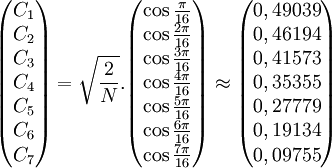
- DCT(8) (méthode de calcul rapide)
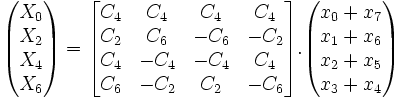
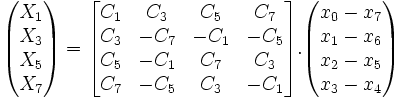
La formule optimisée pour une DCT unidimensionnelle est souvent utilisée telle quelle pour son utilisation dans l'espace bidimensionnel (par transposition et composition) ; cette formule permet de réduire de façon spectaculaire le calcul de 1024 multiplications (formule de base) à 256 multiplications seulement dans le traitement d'un bloc image 8x8 (deux passes de 32 multiplications pour chaque ligne de 8 valeurs) ; cependant, des optimisations sont encore possible en optimisant la composition elle même des deux passes (horizontale et verticale) pour réduire encore de 256 à 91 multiplications seulement (voire moins selon des recherches plus récentes).
On notera aussi que la première matrice ci-dessus permet aussi une réécriture de nombreuses multiplications communes (et donc en fait la formule ci-dessus nécessite beaucoup moins que les 32 multiplications, en fait 16 si on regroupe les sous-expressions communes). On pourrait encore décomposer facilement la première matrice car elle est elle-même une transformée DCT dans R4, décomposable en deux sous-matrices de R2.
De nombreuses études ont montré comment cette transformée peut être optimisée en fonction des contraintes, notamment quand la transformée est utilisée pour la compression, car la transformée permet de concentrer l'essentiel de l'énergie dans les coefficients obtenus xi d'indice faible, les autres concentrant peu d'énergie ont une contribution faible sur le signal spatial initial et sont réduits à zéro lors des étapes de quantification. Ainsi, la précision nécessaire pour représenter les derniers coefficients est plus faible voire nulle, et les coefficients constants Ci utilisés pour le calcul des multiplications scalaires peuvent faire l'objet d'optimisation spécifique, en fixant leur précision, et en utilisant des techniques de multiplication par un nombre réduit d'additions-décalages sans avoir besoin d'utiliser une multiplication générique.
Néanmoins, cet algorithme de calcul (présenté tel quel, il calcule la DCT unidimensionnelle à 8 points avec 16 multiplications) est à la base de toutes les optimisations suivantes par factorisation des sous-matrices. L'algorithme de Loeffler[2] est actuellement le plus efficace ayant été publié (avec 11 multiplications pour la même DCT à 8 points au lieu de 16 avec l'algorithme de Chen, toutefois certains coefficients subissent deux multiplications et cela pourrait rendre l'algorithme moins stable). Il a même été demontré que le nombre minimum théorique de multiplications nécessaires pour la transformation DCT à 8 points ne peut être inférieur à 11, ce qui fait que les algorithmes à 11 multiplications scalaires sont optimums en termes de performance brute (ils se différencient seulement en termes de stabilité suivant l'ordre dans lequel les multiplications sont réalisées, et la précision dès lors nécessaire pour les produits intermédiaires).
Cependant l'algorithme de Loeffler regroupe 8 des 11 multiplications scalaires sur les sorties, ce qui permet de regrouper ces multiplications avec l'étape suivante de quantification (ce qui en fait tout l'intérêt): pour une transformée 2D 8×8, il faut 8×11 multiplications pour la transformée des lignes, et seulement 8×3 multiplications pour les colonnes, soit un total de 112 multiplications (au lieu de 256 avec l'algorithme de Chen) si les 64 dernières multiplications scalaires sont effectuées avec la quantification. Plus de détails sont disponibles dans les normes de compression JPEG et MPEG.
DCT-III
La DCT-III est la transformée inverse de la DCT-II. Elle est plus connue sous le nom de "DCT Inverse" et son acronyme (anglais) "IDCT".
De la même manière que pour la DCT-I, on peut rendre cette transformation orthogonale en multipliant x0 par √2. Cette forme normalisée est très utilisée en pratique mais casse la correspondance avec la DFT.
Exemple pour N = 8
En reprenant l'exemple ci-dessus, on obtient une décomposition inverse (ici orthogonalisée) également utilisée dans l'algorithme de Chen :
- IDCT(8) (méthode de calcul rapide)
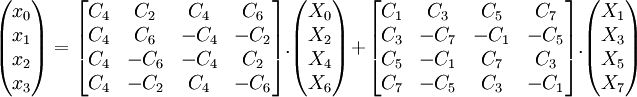
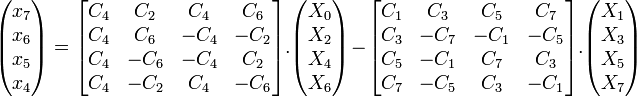
Là aussi, l'évaluation scalaire de ce produit matriciel contient de nombreuses sous-expressions communes permettant des réductions du nombre de multiplications scalaires nécessaires.
/* * Calcul d'une IDCT 2D en 2 IDCT 1D sur les lignes et les colonnes. * (Ici en flottant simple précision, 12 multiplications par IDCT 1D) * Factorisation utilisée ici (Normalisée avec c4=1): * * // Partie gauche * f0 = (x0+x4); * f1 = (x0-x4); * f2 = c6*(x2+x6) + (c2-c6)*x2; * f3 = c6*(x2+x6) + (-c2-c6)*x6; * * // Partie droite * e0 = c3*(x1+x3+x5+x7) + ( c5 - c3)*(x1+x5) + ( c1+c3-c5-c7)*x1 + ( c7 - c3)*(x1+x7); * e1 = c3*(x1+x3+x5+x7) + (-c5 - c3)*(x3+x7) + ( c1+c3+c5-c7)*x3 + (-c1 - c3)*(x3+x5); * e2 = c3*(x1+x3+x5+x7) + ( c5 - c3)*(x1+x5) + ( c1+c3-c5+c7)*x5 + (-c1 - c3)*(x3+x5); * e3 = c3*(x1+x3+x5+x7) + (-c5 - c3)*(x3+x7) + (-c1+c3+c5-c7)*x7 + ( c7 - c3)*(x1+x7); * * out[0] = f0 + f2 + e0; * out[1] = f1 + f3 + e1; * out[2] = f1 - f3 + e2; * out[3] = f0 - f2 + e3; * out[4] = f0 - f2 - e3; * out[5] = f1 - f3 - e2; * out[6] = f1 + f3 - e1; * out[7] = f0 + f2 - e0; */ #define CLAMP(i) if (i & 0xFF00) i = (((~i) >> 15) & 0xFF); // Normalised to c4=1 #define c3 1.175875602f #define c6 0.541196100f #define k1 0.765366865f // c2-c6 #define k2 -1.847759065f // -c2-c6 #define k3 -0.390180644f // c5-c3 #define k4 -1.961570561f // -c5-c3 #define k5 1.501321110f // c1+c3-c5-c7 #define k6 2.053119869f // c1+c3-c5+c7 #define k7 3.072711027f // c1+c3+c5-c7 #define k8 0.298631336f // -c1+c3+c5-c7 #define k9 -0.899976223f // c7-c3 #define k10 -2.562915448f // -c1-c3 void idct(short *block,unsigned char *dest) { float x0,x1,x2,x3,x4,x5,x6,x7; float e0,e1,e2,e3; float f0,f1,f2,f3; float x26,x1357,x15,x37,x17,x35; float out[64]; short v; // Lignes for(int i=0;i<8;i++) { x0 = (float)block[0+i*8]; x1 = (float)block[1+i*8]; x2 = (float)block[2+i*8]; x3 = (float)block[3+i*8]; x4 = (float)block[4+i*8]; x5 = (float)block[5+i*8]; x6 = (float)block[6+i*8]; x7 = (float)block[7+i*8]; // Partie gauche f0 = (x0+x4); f1 = (x0-x4); x26 = c6*(x2+x6); f2 = x26 + k1*x2; f3 = x26 + k2*x6; // Partie droite x1357 = c3*(x1+x3+x5+x7); x15 = k3*(x1+x5); x37 = k4*(x3+x7); x17 = k9*(x1+x7); x35 = k10*(x3+x5); e0 = x1357 + x15 + k5*x1 + x17; e1 = x1357 + x37 + k7*x3 + x35; e2 = x1357 + x15 + k6*x5 + x35; e3 = x1357 + x37 + k8*x7 + x17; out[0+i*8] = f0 + f2 + e0; out[1+i*8] = f1 + f3 + e1; out[2+i*8] = f1 - f3 + e2; out[3+i*8] = f0 - f2 + e3; out[7+i*8] = f0 + f2 - e0; out[6+i*8] = f1 + f3 - e1; out[5+i*8] = f1 - f3 - e2; out[4+i*8] = f0 - f2 - e3; } // Colonnes for(int i=0;i<8;i++) { x0 = out[i+8*0]; x1 = out[i+8*1]; x2 = out[i+8*2]; x3 = out[i+8*3]; x4 = out[i+8*4]; x5 = out[i+8*5]; x6 = out[i+8*6]; x7 = out[i+8*7]; // Partie gauche f0 = (x0+x4); f1 = (x0-x4); x26 = c6*(x2+x6); f2 = x26 + k1*x2; f3 = x26 + k2*x6; // Partie droite x1357 = c3*(x1+x3+x5+x7); x15 = k3*(x1+x5); x37 = k4*(x3+x7); x17 = k9*(x1+x7); x35 = k10*(x3+x5); e0 = x1357 + x15 + k5*x1 + x17; e1 = x1357 + x37 + k7*x3 + x35; e2 = x1357 + x15 + k6*x5 + x35; e3 = x1357 + x37 + k8*x7 + x17; // Tronque dans l'intervalle [0,255] // Note: La normalisation avec c4=1 implique une division par 8 // Le +1028 sert à recentrer et à arrondir la valeur du pixel // v = (short)((.+.+.)/8.0 + 128.5f); v = (short)((f0 + f2 + e0) + 1028.0f) >> 3; CLAMP(v); dest[i+8*0] = (uchar)v; v = (short)((f1 + f3 + e1) + 1028.0f) >> 3; CLAMP(v); dest[i+8*1] = (uchar)v; v = (short)((f1 - f3 + e2) + 1028.0f) >> 3; CLAMP(v); dest[i+8*2] = (uchar)v; v = (short)((f0 - f2 + e3) + 1028.0f) >> 3; CLAMP(v); dest[i+8*3] = (uchar)v; v = (short)((f0 - f2 - e3) + 1028.0f) >> 3; CLAMP(v); dest[i+8*4] = (uchar)v; v = (short)((f1 - f3 - e2) + 1028.0f) >> 3; CLAMP(v); dest[i+8*5] = (uchar)v; v = (short)((f1 + f3 - e1) + 1028.0f) >> 3; CLAMP(v); dest[i+8*6] = (uchar)v; v = (short)((f0 + f2 - e0) + 1028.0f) >> 3; CLAMP(v); dest[i+8*7] = (uchar)v; } }
DCT-IV
La DCT-IV est une matrice orthogonale.
Références
- ↑ W. Chen, C.H. Smith, and S.C. Fralick, "A fast computational algorithm for the discrete cosine transform," IEEE Trans. Commun., Vol. COM-25, pp 1004-1009, Sep. 1977.
- ↑ C. Loeffler, A. Ligtenberg, and G. Moschytz. Practical Fast 1D DCT Algorithms With 11 Multiplications. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pages 988--991, 1989
- (en) A computationally efficient high-quality Cordic-based DCT, B. Heyne, C. C. Sun, J. Goetze et S. J. Ruan : amélioration de l'algorithme de calcul de Loeffler par la transformation de Cordic, analyse de complexité et comparaison des performances obtenues, pour le calcul de la transformée DCT à 8 points (PDF).
Bibliographie
- K. R. Rao and P. Yip, Discrete Cosine Transform: Algorithms, Advantages, Applications (Academic Press, Boston, 1990).
- A. V. Oppenheim, R. W. Schafer, and J. R. Buck, Discrete-Time Signal Processing, second edition (Prentice-Hall, New Jersey, 1999).
- S. A. Martucci, "Symmetric convolution and the discrete sine and cosine transforms," IEEE Trans. Sig. Processing SP-42, 1038-1051 (1994).
- Matteo Frigo and Steven G. Johnson: FFTW, http://www.fftw.org/. A free (GPL) C library that can compute fast DCTs (types I-IV) in one or more dimensions, of arbitrary size. Also M. Frigo and S. G. Johnson, "The Design and Implementation of FFTW3," Proceedings of the IEEE 93 (2), 216–231 (2005).
- E. Feig, S. Winograd. "Fast algorithms for the discrete cosine transform," IEEE Transactions on Signal Processing 40 (9), 2174-2193 (1992).
- P. Duhamel and M. Vetterli, "Fast Fourier transforms: a tutorial review and a state of the art," Signal Processing 19, 259–299 (1990).
- John Makhoul, "A fast cosine transform in one and two dimensions," IEEE Trans. Acoust. Speech Sig. Proc. 28 (1), 27-34 (1980).
Voir aussi
- Transformée de Fourier
- Transformée de Fourier discrète
- Compression JPEG - DCT appliquée au format JPEG
Liens externes
 Portail des mathématiques
Portail des mathématiques
Catégories : Transformée | Analyse harmonique discrète | Imagerie numérique | Transformée du signal

![X_k = \frac{1}{2} \left( x_0 + (-1)^k x_{N-1} \right) + \sum_{n=1}^{N-2}{x_n \cos\left[ \frac{\pi}{N-1} n k \right]}](/pictures/frwiki/100/df227ada4d59477945da088ff32b0dae.png)
![X_k = \sum_{n=0}^{N-1}{x_n \cos\left[ \frac{\pi}{N} \left( n + \frac{1}{2} \right) k \right]}](/pictures/frwiki/100/dfeb37421699b1455558542c18af0a4e.png)
![X_k = \frac{1}{2} x_0 + \sum_{n=1}^{N-1}{x_n \cos\left[ \frac{\pi}{N} n \left( k + \frac{1}{2} \right) \right]}](/pictures/frwiki/49/1744792055ca63fa6a33a4f1d0e7f630.png)
![X_k = \sum_{n=0}^{N-1}{x_n \cos\left[ \frac{\pi}{N} \left( n+\frac{1}{2} \right) \left( k + \frac{1}{2} \right) \right]}](/pictures/frwiki/54/6407189b486596115cd9fb882ee7a9cd.png)
Wikimedia Foundation. 2010.